Facial Expression Recognition — Part 1: Solution Pipeline on Ubuntu
Pre-processing the data set, training the model and running inference on the desktop
Multiple techniques have been proposed for facial expression recognition (FER), technology designed to identify facial expressions like anger, disgust, fear, happiness, sadness, surprise and no emotion (neutral). Recognizing facial expressions has ramifications for business and society. Entertainment companies can use FER to gauge audience reaction in real time, and airport security has tested it for biometrically verifying identity.
The following describes the pipeline of one approach to FER, including tests on images of human faces bearing various expressions.
Setting up
The data set contains the grayscale images of human faces sized at 48×48 pixels. The training set contains 35,888 examples with three columns:
- Pixels — contains space-separated pixel values for each image
- Usage — differentiates training and test images
- Emotion — consists of numeric value from 0 to 6, where 0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral
Here is the project hierarchy:
Loading the data set
pandas, a python library with powerful data structures for data manipulation, makes it easier to read the CSV file and store it as training data and test data.
df = pd.read_csv('fer 2013.csv')train_data = df[df['Usage'] == 'Training'].copy()test_data = df[df['Usage'] == 'PublicTest'].copy()train_data['pixels'] = train_data['pixels'].apply(lambda \ m:np.asarray(m.split(' '), dtype='float32'))test_data['pixels'] = test_data['pixels'].map(lambda \ m:np.asarray(m.split(' ')))Pre-processing the data set
The FerHelper class is used for formatting the data set for the model. The class has three methods:
- set_up_images() — Converts the image data as 48x48 NumPy array
- one_hot_encode() — Used for one-hot encoding of input image labels
- next_batch() — Used during training of model when images are fed to the model in batches
class FerHelper():def __init__(self): self.i = 0 self.train_images = None self.train_labels = None self.test_images = None self.test_labels = Nonedef one_hot_encode(vec, vals=7): n = len(vec) out = np.zeros((n, vals)) out[range(n), vec] = 1 return outdef set_up_images(self, train, test): print ('setting up training images and labels') j = 0 self.train_images = np.zeros((len(train), 48, 48)) for pixels in train_data['pixels']: self.train_images[j] = pixels.reshape(48, 48) j += 1 self.train_images = self.train_images.reshape((len(train), \48,48,1)) self.train_images = self.train_images.astype('float32') / 255 self.train_labels = one_hot_encode(train_data['emotion'].values) print ('setting up testing images and labels') k = 0 self.test_images = np.zeros((len(test), 48, 48)) for test_pixels in test_data['pixels']: self.test_images[k] = test_pixels.reshape((48, 48)) k += 1 self.test_images = np.expand_dims(self.test_images, 3) self.test_images = self.test_images.astype('float32') / 255 self.test_labels = one_hot_encode(test_data['emotion'].values)def next_batch(self, batch_size): batch_size = self.train_images[self.i:self.i + \batch_size].shape[0] x = self.train_images[self.i:self.i + \batch_size].reshape(batch_size, 48, 48, 1) y = self.train_labels[self.i:self.i + batch_size] self.i = (self.i + batch_size) % len(self.train_images) return x, yArchitecture of the CNN model
The model is trained using the TensorFlow framework. The architecture for training the FER data set to classify emotions is as follows:
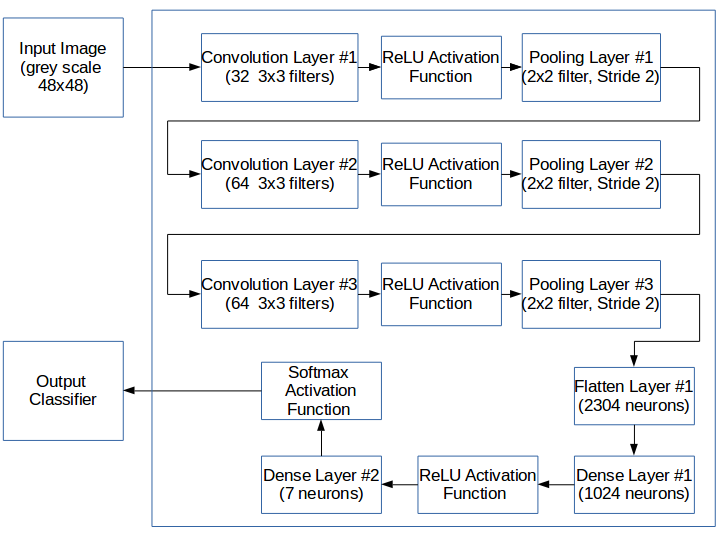
In the following code, the method neural_network_model() defines the model architecture. The model accepts the input image of size 48×48 and returns a 1×7 array of output with the probabilities of each class. accepts the input image of size 48×48 and returns a 1×7 array of output with the probabilities of each class.
def neural_network_model(input_x): # convolutional layer 1 with tf.name_scope('conv_layer1'): output_conv1 = tf.layers.conv2d( inputs=input_x, filters=32, kernel_size=[3, 3], padding="same", activation=tf.nn.relu) with tf.name_scope('maxpool_at_layer1'): output_maxpool1 = tf.layers.max_pooling2d(inputs=output_conv1, \ pool_size=[2, 2], strides=2) # convolutional layer 2 with tf.name_scope('conv_layer2'): output_conv2 = tf.layers.conv2d( inputs=output_maxpool1, filters=64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu) with tf.name_scope('maxpool_at_layer2'): output_maxpool2 = tf.layers.max_pooling2d(inputs=output_conv2, \ pool_size=[2, 2], strides=2) # convolutional layer 3 with tf.name_scope('conv_layer3'): output_conv3 = tf.layers.conv2d( inputs=output_maxpool2, filters=64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu) with tf.name_scope('maxpool_at_layer3'): output_maxpool3 = tf.layers.max_pooling2d(inputs=output_conv3, \ pool_size=[2, 2], strides=2) # flattening with tf.name_scope('flattened'): flatten_conv = tf.reshape(output_maxpool3, [-1, 6 * 6 * 64]) # Processing at fc1 with tf.name_scope('Fc1'): activated_output_fc1 = tf.layers.dense(inputs=flatten_conv, \ units=1024, activation=tf.nn.relu) with tf.name_scope('FC2'): activated_output_fc2 = tf.layers.dense(inputs= \ activated_output_fc1, units=7, activation=tf.nn.softmax) return activated_output_fc2Training the model
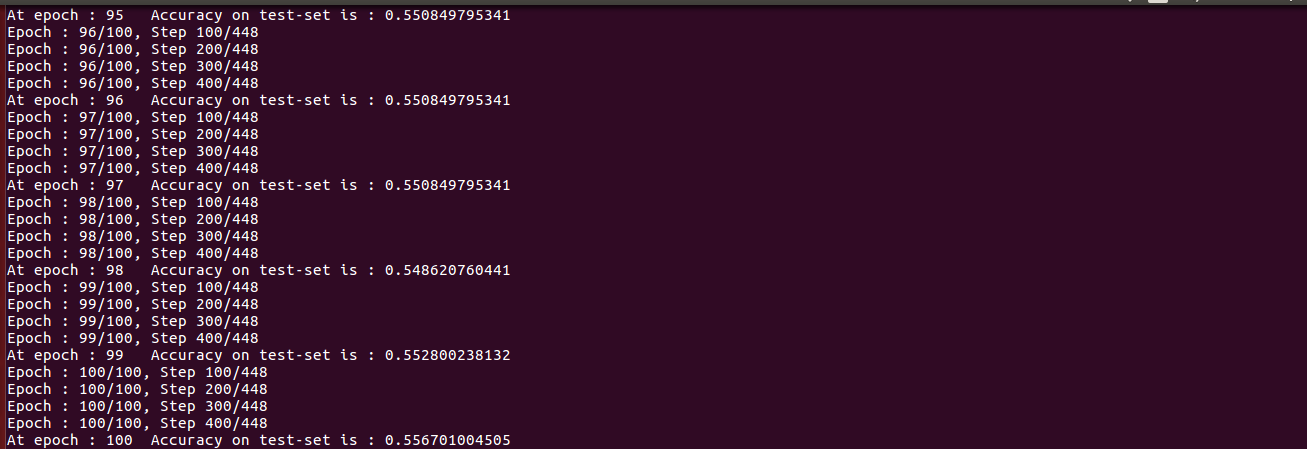
The following code trains the model for 100 epochs and saves the model’s checkpoints. At every epoch it has three files with .meta, .data and .index extensions.
def build_and_train_model(x, train_data, test_data): pred_res = neural_network_model(x) saver = tf.train.Saver() train_len = len(train_data) batch_size = 64 # before tf.session, run these two lines ch = FerHelper() ch.set_up_images(train_data, test_data)
with tf.name_scope("cross_entropy"): cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits \ (logits=pred_res, labels=y_true)) print ('in cross_entropy') with tf.name_scope('optimizer'): optimizer = tf.train.AdamOptimizer(3e-4).minimize(cross_entropy) print('in optimizer') with tf.name_scope('truth_table_bool'): truth_table_bool= tf.equal(tf.argmax(pred_res, 1), tf.argmax(y_true, 1)); with tf.name_scope('truth_table_int'): truth_table_int = tf.cast(truth_table_bool, tf.float32) with tf.name_scope('correct_preds'): correct_preds = tf.reduce_mean(truth_table_int) epoch = 100 steps = int(train_len / batch_size) with tf.Session() as sess: writer = tf.summary.FileWriter('./board-logs/', sess.graph) sess.run(tf.global_variables_initializer()) for ep in range(1, epoch + 1): for step in range(1, steps): if (step%100 == 0): print ('Epoch : {}/{}, Step {}/{}'.format(ep, epoch, step, steps)) batch = ch.next_batch(batch_size) sess.run(optimizer, feed_dict={x: batch[0], y_true: batch[1]}) acc_result = sess.run(correct_preds, feed_dict={x: ch.test_images, \ y_true: ch.test_labels}) model_title = './checkpoints/fer-model-' + str(ep) saver.save(sess, model_title) tf.train.write_graph(sess.graph.as_graph_def(), '.', model_title + \ '.pbtxt', as_text=True) print('At epoch : {} \tAccuracy on test-set is : {}'.format (ep, \ acc_result)) writer.close()The output to screen shows that the model gives ~56% accuracy on the validation set during training.
Converting the model to DLC
As described above, the Qualcomm Neural Processing SDK for AI includes a snpe-tensorflow-to-dlc tool for converting the .meta file to the deep learning container (DLC) format required by the SDK. Run the tool from the directory containing the .meta file, and use the following input arguments:
- Input Layer name: x
- Input Shape: 1, 48, 48, 1
- Output Layer name: truth_table_bool/ArgMax
That is:
$ snpe-tensorflow-to-dlc -- graph fer-model-100.meta -i x 1,48,48,1 -- out_node truth_table_bool/ArgMax -- dlc fer.dlcThe resulting fer.dlc file is in the format required by the SDK.
Running inference on Ubuntu using the Qualcomm Neural Processing SDK for AI
The SDK requires the NumPy array, which is stored in raw form as an input for running inference against a model. The following code generates the pre-processed array as raw-file.txt:
import numpy as npimport cv2from os import listdirfrom os.path import isfile, join
myInputPath = './data/input/'myOutputPath = './data/raw-images/'
allImages=[f for f in listdir(myInputPath) if isfile(join(myInputPath, f))]raw_images = []
for i in allImages: ifile = myInputPath+i ofile = myOutputPath + ifile.split('/')[-1].split('.')[0] + '.raw' raw_images.append(ofile.split('/')[-1])
img = cv2.imread(ifile, 0) img = cv2.resize(img, (48, 48))
np_arr = np.array(img).astype('float32') np_arr.tofile(ofile)
with open(myOutputPath+"raw-file.txt", "w") as myfile: for rimg in raw_images: myfile.write(myOutputPath+rimg+'\n')Run the following command from the base location of the .dlc file:
$ snpe-net-run - - container fer.dlc - -input_list ./data/raw-images/raw-file.txtThat generates an output folder in which the results are stored. It contains the output tensor data of 7 probabilities for 7 categories (emotions).
Displaying the results
The SDK includes a show_inceptionv3_classifications.py script to check the results from classifying the content of the output folder generated in the previous step. Modify show_inceptionv3_classifications.py script as follows:
- Update the number of labels field, which states the total number of facial expressions classified by your model (e.g., for 7 different expressions, number of labels = 7)
- Update the path of cur_results_file to your snpe-net-run results folder.
- Save the script.
Now, run the script from the base location of the .dlc file to generate an output label-file
$ python $SNPE_ROOT/models/inception_v3/scripts/ show_inceptionv3_classifications.py -i ./data/raw-images/raw-file.txt -o output -l ./data/label-file.txtwhere raw-file.txt contains the path to raw images and label-file.txt contains the labels of the model.
This is an example of typical output:

Qualcomm Neural Processing SDK is a product of Qualcomm Technologies, Inc. and/or its subsidiaries.