Computer Vision CNN Architectures
Three classic network architectures for combining layers to increase accuracy
In essence, the neural network replicates the same process that humans undergo in learning from their mistakes. In addition to that neural process, convolution in CNN performs the process of feature extraction.
Here are three classic networks and the architecture that underlies each one.
LeNet-5
LeNet is the first CNN architecture and an example of a gradient-based learning.
LeNet was trained on the Modified NIST or MNIST data set and designed to identify handwritten numbers on checks. The weights and hyperparameters are varied so that the gradient divergence on the loss function reaches a minimum. But as used in computer vision, the weights and hyperparameters in LeNet were engineered manually. The input for LeNet is 32×32, which is visible without magnification and far larger than the size of the characters as originally written. The large input allows for minute features from the image to be captured.
LeNet consists of convolution layers, subsampling layers and fully connected layers. (For a diagram of the architecture of LeNet-5, see http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf, page 7).
- The convolution layers extract the features from the images.
- The subsampling layer consists of applying the activation function to the input from convolution layers and performing the pooling process on the output obtained from applying activation function.
- A fully connected layer connects each neuron of one layer to every neuron of another layer. The last layer of the fully connected layer is reserved for an activation function to assist in classification.
AlexNet
The LeNet architecture shows that increasing the depth of the network increases accuracy. The AlexNet architecture incorporates that lesson. AlexNet consists of five Convolution layers and three fully connected layers.
AlexNet uses ReLu (Rectified Linear Unit) as its activation function. ReLu is used instead of traditional sigmoid or tanh functions for introducing non-linearity into the network. Compared to traditional activation functions, ReLu is more responsive to positive values and zero-responsive to negative values, ensuring that not all the neurons are active at any given time. The computation time required for ReLu is also lower than that for sigmoid and tanh.
The other advantage of ReLu is that it allows for removing (dropping) dead neurons, as shown below.
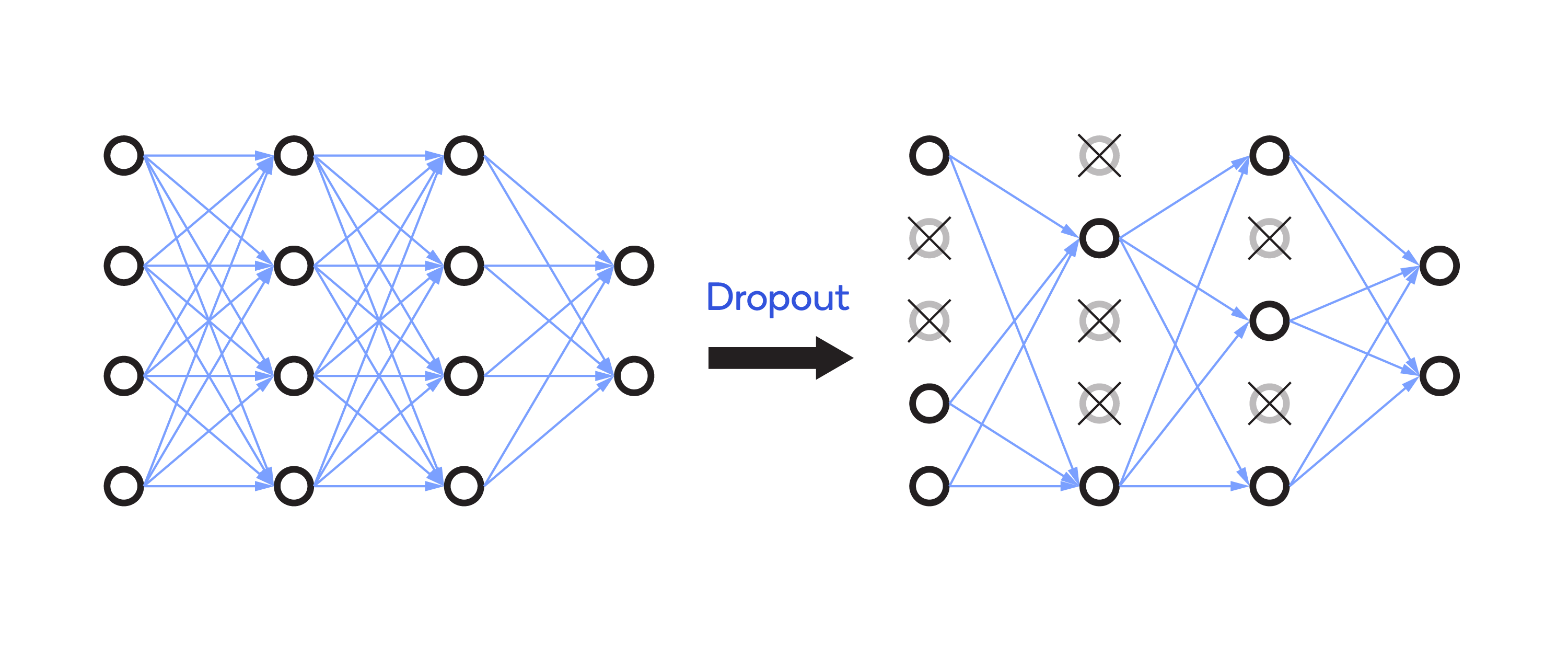
Dropout in AlexNet
The developer can set the ratio for dropping inactive neurons. Dropout helps avoid overfitting in AlexNet.
When trained on the ImageNet LSVRC-2012 data set, AlexNet achieved a relatively low error rate of 15.3% compared to the error rate of 26.2% for a non-CNN. (For a diagram of the architecture of AlexNet, see https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf, page 5.
VGG-Net (Visual Geometry Group)
AlexNet demonstrates the value of using larger filters. To attain the state of the art, VGG-Net uses 3×3 filters in a series. That increases the depth of the network, which is effective in detecting the features in an image. (For a diagram of the architecture of VGG-Net, trained and tested on a data set containing 1000 classes, with 1000 images in each class, see https://www.researchgate.net/profile/Clifford_Yang/publication/325137356/figure/fig2/AS:670371271413777@1536840374533/llustration-of-the-network-architecture-of-VGG-19-model-conv-means-convolution-FC-means.jpg