DSP Processor
Qualcomm Technologies developed the Hexagon Digital Signal Processor (DSP) as a world class processor with both CPU and DSP functionality to support deeply embedded processing needs of the mobile platform for both multimedia and modem functions. It is an advanced, variable instruction length, Very Long Instruction Word (VLIW) processor architecture with hardware multi -threading. The Hexagon architecture and family of cores provides Qualcomm Technologies a competitive advantage in performance and power efficiency for modem and multi-media applications and is a key component of Snapdragon® processors.
| Hexagon Core Architecture | ||||
|---|---|---|---|---|
| Hexagon 400 | Hexagon 500 | Hexagon 600 | ||
| Key Attributes | Fixed Point | Floating Point | Hexagon Vector eXtensions (HVX) | |
Snapdragon Chipsets (SDxxx) | Premium Tier | 801, 805, 808, 810 | 820, 821 | |
| High Tier | 602A | 615, 161, 617, 625, 650, 652 | ||
| Mid Tier | 410, 412, 415, 430 | |||
| Low Tier | 208, 210, 212 | |||
| SDK Version | AddOn_600 | SDK 2.0 | SDK 3.0 | |
| Command Line Tools | 5.0, 5.1 | 5.0, 5.1, 6.2, 6.4 | 7.2, 7.3 | |
| RTOS | QuRT | QuRT | QuRT | |
Hexagon DSP Processor Background:
Qualcomm Technologies began development of a new DSP processor architecture and high-performance implementation in the Fall of 2004. In 2011 the Hexagon Access program was started to allow customers to program the DSP and thus exploit the power & performance benefits of offloading the ARM cores for performance, reduced power dissipation, or concurrency requirements. As of 2012, multiple Hexagon cores form the processing engine behind virtually every commercially shipping 4G LTE modem by Qualcomm Technologies. The “Hexagon DSP” core is now in its 5th generation and is integrated inside all recent Qualcomm Technologies modem and application chips. At Uplinq 2013, we released the first publicly available development environment for the Hexagon DSP, the Hexagon SDK.
Hexagon cores are optimized for both high performance and energy efficiency. Energy efficiency is often the more critical metric. Rather than pushing performance through MHz, the designs strive for high levels of work per cycle, but at a reduced clock speed. Keeping the speed targets low allows the implementation to avoid many of the power-costly design methods that are typical of high speed design. One of the challenges with multi-threading is to have the power scale with the number of threads running. Through carefully orchestrated hierarchical clock gating, near perfect power scaling is achieved. Hexagon cores use a semi-custom physical design methodology with customizations oriented to power reduction
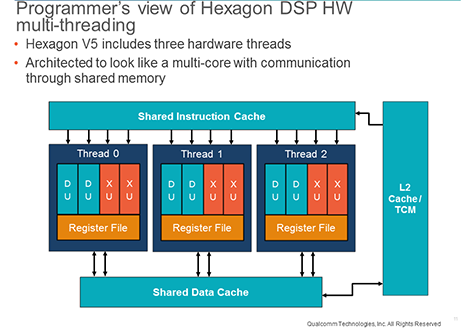
All versions of the Hexagon DSP core are hardware multi-threaded to enable superior concurrency needed in mobile applications. Implementations have evolved from simple Interleaved Multi-Threading (IMT) to more advanced prioritized scheduling to obtain the maximum efficiency to schedule as many execution slots as possible. The number of hardware threads has changed over the generations to meet various product and application needs. The initial Hexagon V1 core supported six threads, but the most recent version of Hexagon DSP, Hexagon V5 features three threads. To the programmer, these hardware threads can be considered as separate processor cores with shared memory, and are programmed using conventional software threading.
The programmer does not need to focus on the threading since the RTOS maps user software threads onto the processors hardware threads. These hardware threads share the entire memory hierarchy including L1. Thus, it is very beneficial for the software to employ threads that cooperate on shared data. To facilitate this, a very fast RTOS kernel has been designed for Hexagon. The RTOS globally schedules the highest priority runnable software threads and always directs interrupts to the lowest-priority hardware thread. Unlike most architectures, the Hexagon instruction set originated and evolved assuming the existence of a multi-threaded implementation. The inherent latency tolerance afforded by multi-threading enabled ISA optimizations that would not otherwise be practical. Hexagon goes beyond conventional VLIW and allows for grouping of both independent and many forms of dependent instructions. As an example, the common load-compare-branch idiom can be expressed in a single Hexagon instruction packet. Such techniques enable extraction of high instruction parallelism even from irregular control-code applications.
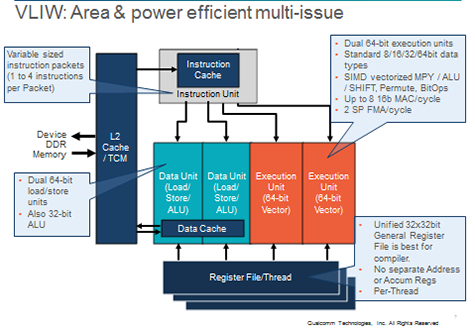
The ISA features a VLIW-style static grouping of instructions. Multi-threading and VLIW are complementary technologies. Multi-threading hides pipeline latencies which make instruction latencies appear low. The perception of low instruction latencies allows the compiler to more effectively utilize the VLIW packets. The Hexagon ISA is a hybrid DSP/CPU that features a 4-issue VLIW comprised of dual load/store slots and dual 64-bit vector execution slots. All instructions operate on a shared 32-entry per-thread register file. Vector operations use register pairs from the general register file. The ISA features a rich set of DSP arithmetic support including 16-bit and 32-bit fractional and complex data types, 32-bit floating-point, and full 64-bit integer arithmetic support. Competitive data from applications such as H.264, AMR-WB and AAC+ will be presented.
A public description of this architecture was recently presented at the 2013 edition of the Hot Chips conference at Stanford University in August.
The processor has been benchmarked against relevant DSP processors by the leading independent company that analyzes Digital Signal Processors, Berkeley Design Technologies Incorporated (BDTI).
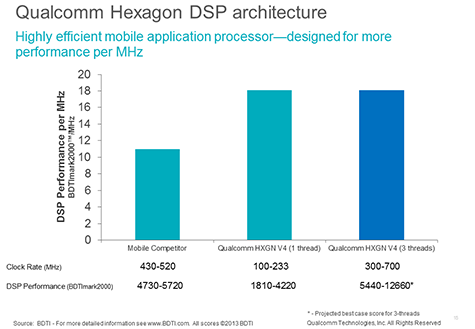
Results of this benchmarking can be found at BDTI’s website.
The Hexagon processor is a hardware multi-threaded, variable instruction length, VLIW processor architecture developed for efficient control and signal processing code execution at low power levels needed for mobile platforms.