Tuning and Optimizing Machine Learning Models
Parameters, hyperparameters, regularization and optimization
In the process of training deep learning models in frameworks compatible with the Qualcomm® Neural Processing SDK, it is a good idea to improve models through tuning and hyperparameter optimization. Why? In any machine learning (ML) pipeline, it becomes necessary to enhance model accuracy and to shorten the time required to reach acceptable accuracy in last-mile training.
Parameters and hyperparameters
Any type of ML is a process of predicting and classifying data, for which a wide variety of machine learning models exists. The learning algorithm upon which every model is based includes parameters — configuration variables internal to the model whose value can be estimated from the data being used to train it.
ML models also have hyperparameters so that they can be tuned for better performance. Hyperparameters are like tuning knobs for achieving better performance.

The context of deep learning includes two particular types of techniques for optimizing and tuning: regularization and optimization.
Regularization
Regularization is a group of techniques for resolving the problems that arise out of overfitting in statistical models. Overfitting causes poor generalization when the model is too complex, such as when the number of parameters is too high compared to the number of data points.
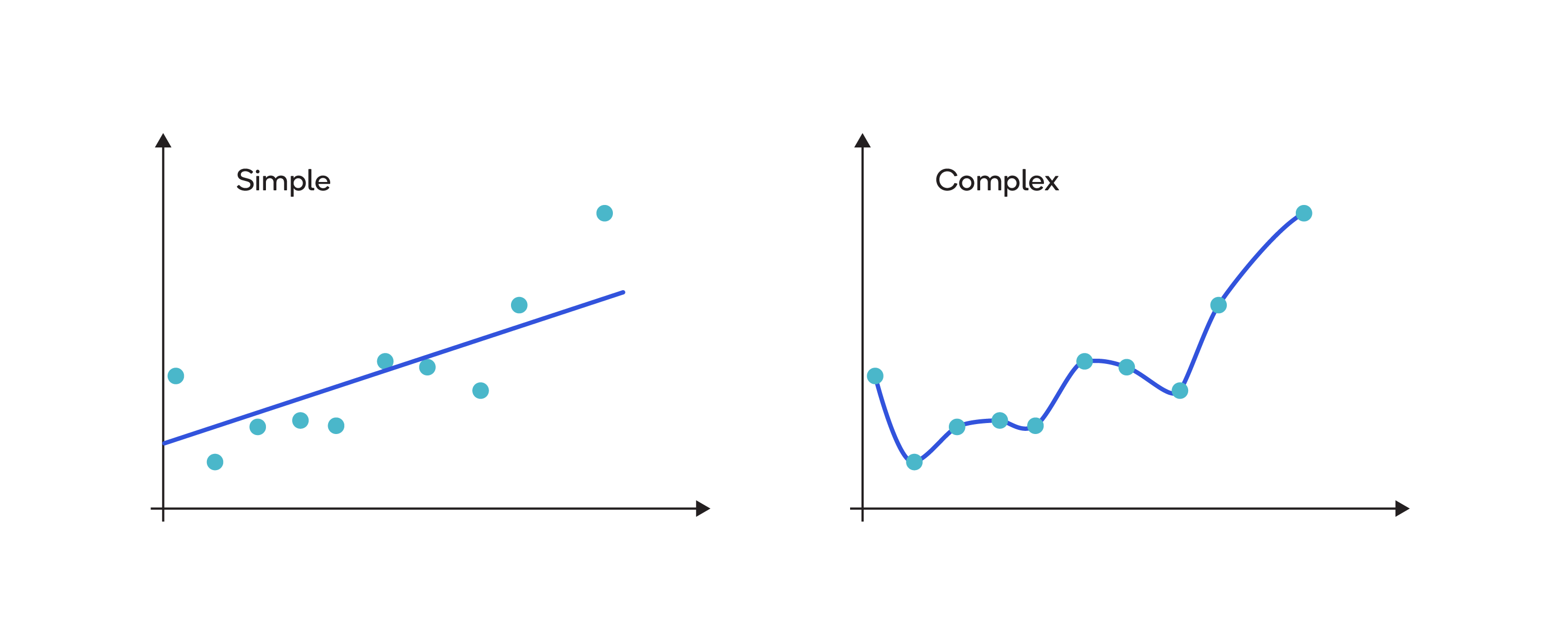
Regularization techniques, including those described below, lead to a preferred level of model complexity so that the model predicts better.
Dropout regularization
The need for dropout regularization (“dropouts”) arises when a large gap is observed between the accuracy of the training set and the test set. The need for dropouts can also arise from overfitting, when a high variance is observed when applying K-fold cross validations.
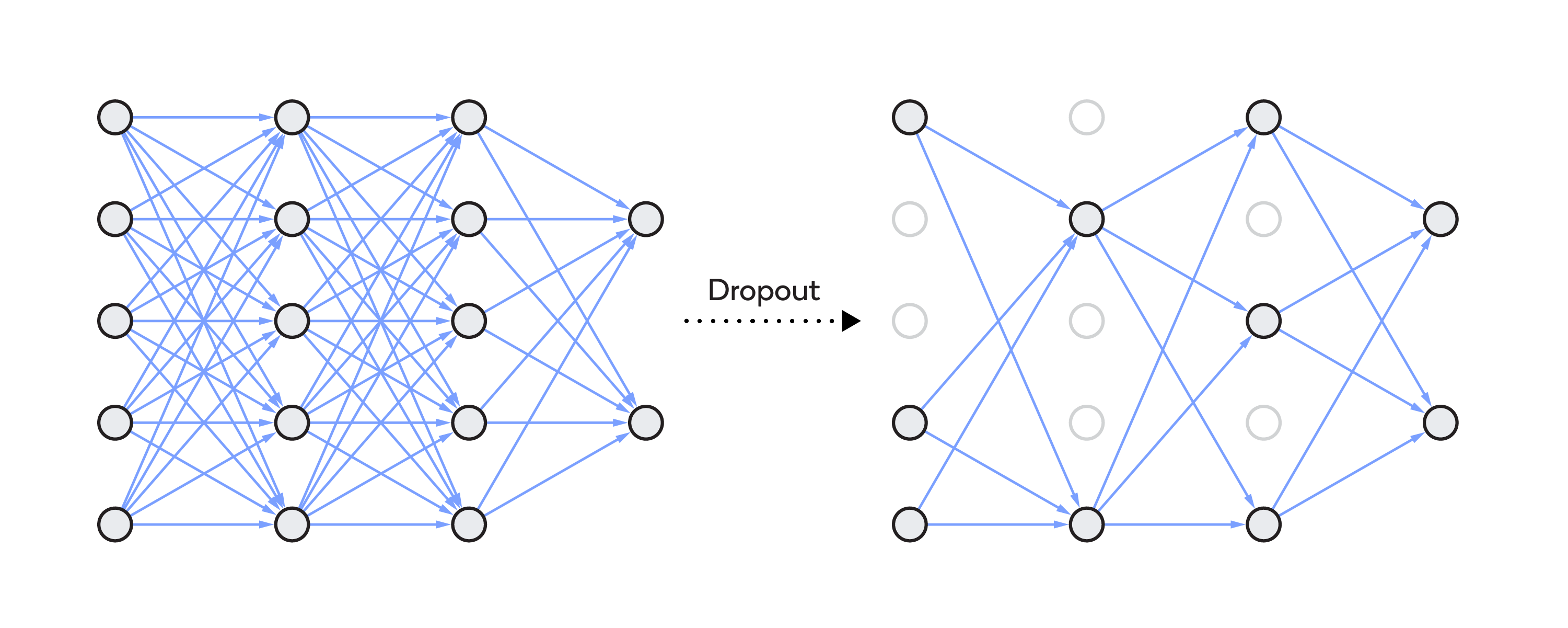
To achieve dropout regularization, some neurons in the artificial neural network are randomly disabled. That prevents them from being too dependent on one another as they learn the correlations. Thus, the neurons work more independently, and the artificial neural network learns multiple independent correlations in the data based on different configurations of the neurons.
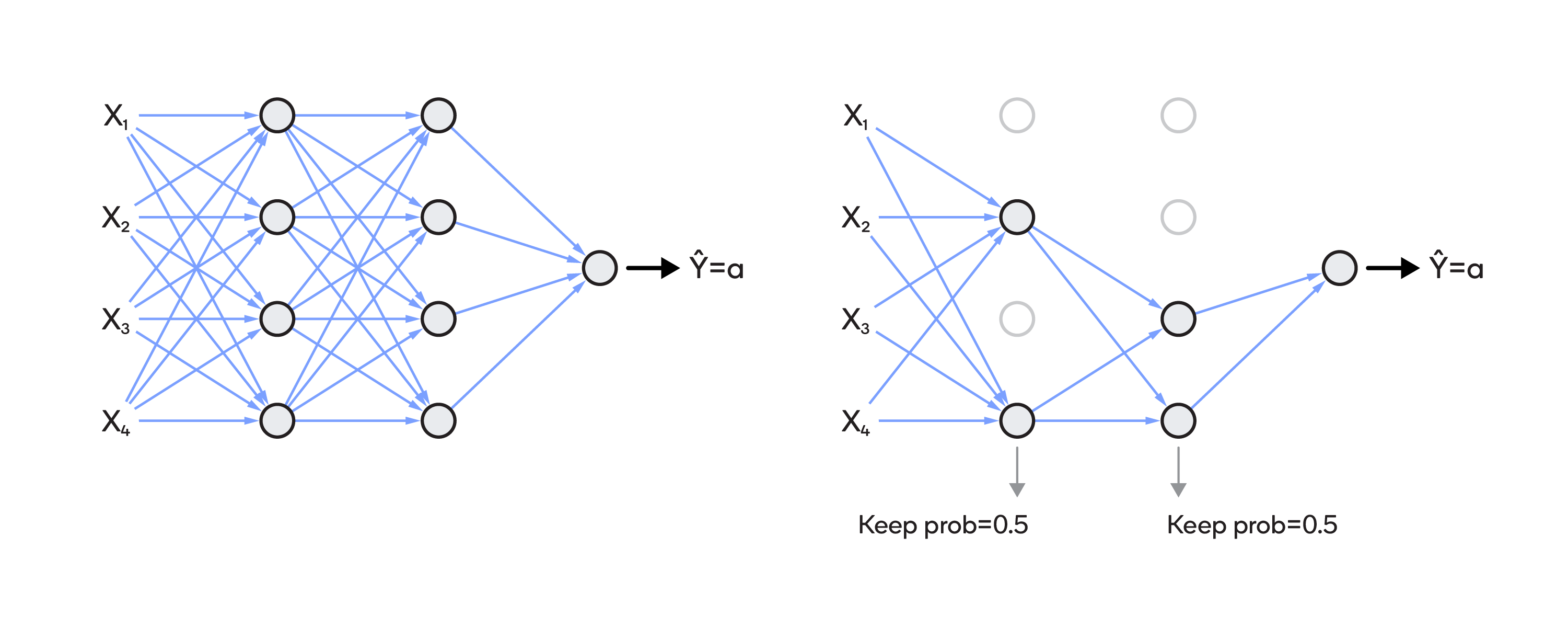
After dropout regularization, the network cannot rely on any single feature since at any given time the feature might be suppressed. The network then spreads out the weights, which avoids putting too much weight on any one feature. That prevents the neurons from learning too much, which can lead to overfitting.
Early stopping
Stopping the training before the weights have converged (“early stopping”) can improve the generalization capability of the deep neural network.
Data collected for training is split into three different sets: training, validation and test. The training set is used for computing the gradient and updating the network weights and biases. The error on the validation set is monitored during the training process. Normally, the error rate on both the training set and the validation set decreases during the initial phase of training. However, the error on the validation set usually rises as the network begins to overfit the data, as shown below.
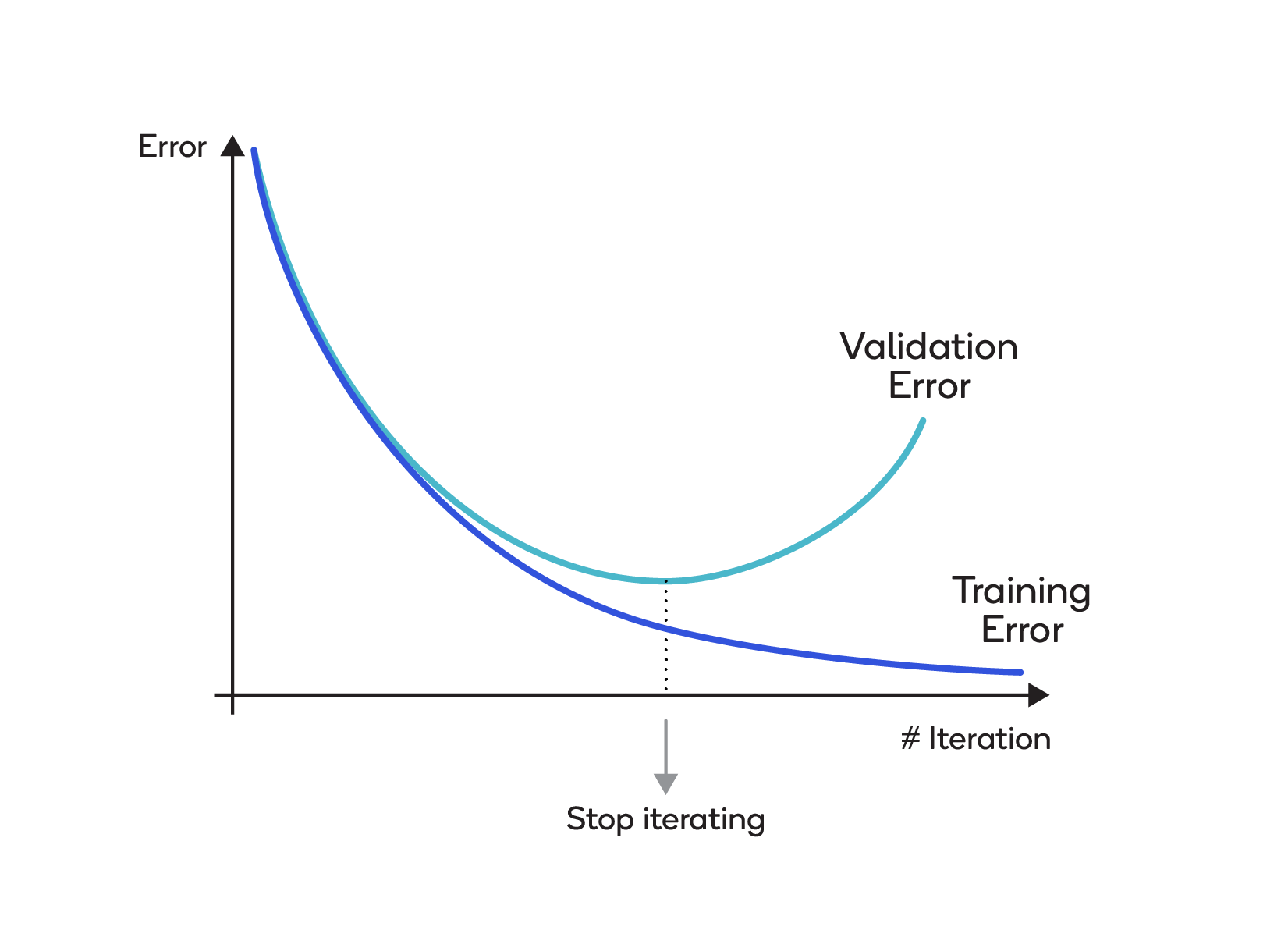
The technique is called “early stopping” because training stops when the validation error swings back upward for a given number of iterations. The weights and biases to be used are those at the low point on the validation error curve.
Although the error on the test set is not used during the training, it can be useful as a control on different models and for plotting during the process of training. That way, if there is a significant discrepancy between the low point on the error curve for the test set and the low point for the validation set, it’s a strong hint that the dataset is poorly divided.
Data augmentation
Data augmentation, or simply using more data for training, can be performed by obtaining more training samples or by augmenting the existing data through clever manipulation.
When data is scarce, it is not always easy for data scientists to obtain more training samples, so augmenting data through manipulation is often the path to pursue. With vision-based data, possible manipulations include the following:
- Changing the colors of the images used to train
- Changing the size of the images
- Flipping the images and using them as surplus to the existing set
Deep neural networks treat each additional image as an individual case, leading to greater insight/features and improved generalization capabilities.
Optimization
As described above, hyperparameters like learning rate and dropout are modified iteratively during the many passes of the model training process. Each pass contains multiple sub-runs for cross-validation; for example, K-fold cross-validation. Through optimization, the hyperparameters are adjusted after each training run for the best outcome based on the scoring metric. This iterative process is also referred to as model tuning.
Each aspect of machine learning is continuously evolving, with new optimization techniques around different applications and models. The following are typical approaches for model tuning in machine learning:
1. Grid search optimization
This is a brute-force approach through a predetermined list of possible combinations. All of the possible values of hyperparameters are listed and looped through in an iterative fashion to obtain the best values.
Grid search takes less time to program and works well if the dimensionality in the feature-vector is low. But as the number of dimensions increases, it takes a long time and becomes cumbersome.
2. Random search optimization
Random search is an improvement on grid search. Instead of an exhaustive search through every combination of hyperparameters, this is a random sample of values. It includes samples from non-uniform probability distributions for continuously valued hyperparameters.
Random search has been proved to produce better results in less time than grid search. In addition, random search allows for a tuning budget to be set independent of the size of your problem (e.g., number of hyperparameters). In other words, the user may set the desired number of iterations and stop at any time.
3. Gradient search
A main drawback of grid search and random search is that they ignore the results obtained after a combination is checked. Worse yet, they don’t use the previous search results when indicating where to look next.
A gradient search, on the other hand, pays attention to recent results. If, for instance, the goal is to minimize error, a gradient search will try to move further downhill. Should the search go undesirably far, algorithms like conjugate gradient search allow for backing up and changing direction at right angles when one line plays out. Another major concern is getting stuck in local minima while looking for the elusive global minimum.
Qualcomm Neural Processing SDK is a product of Qualcomm Technologies, Inc. and/or its subsidiaries.