Quantization Workflow
Developers building ML solutions for devices powered by Snapdragon® mobile platforms using the Qualcomm® Neural Processing SDK, can incorporate AI Model Efficiency Toolkit (AIMET) into their model-building workflow as shown in the diagram and outlined below.
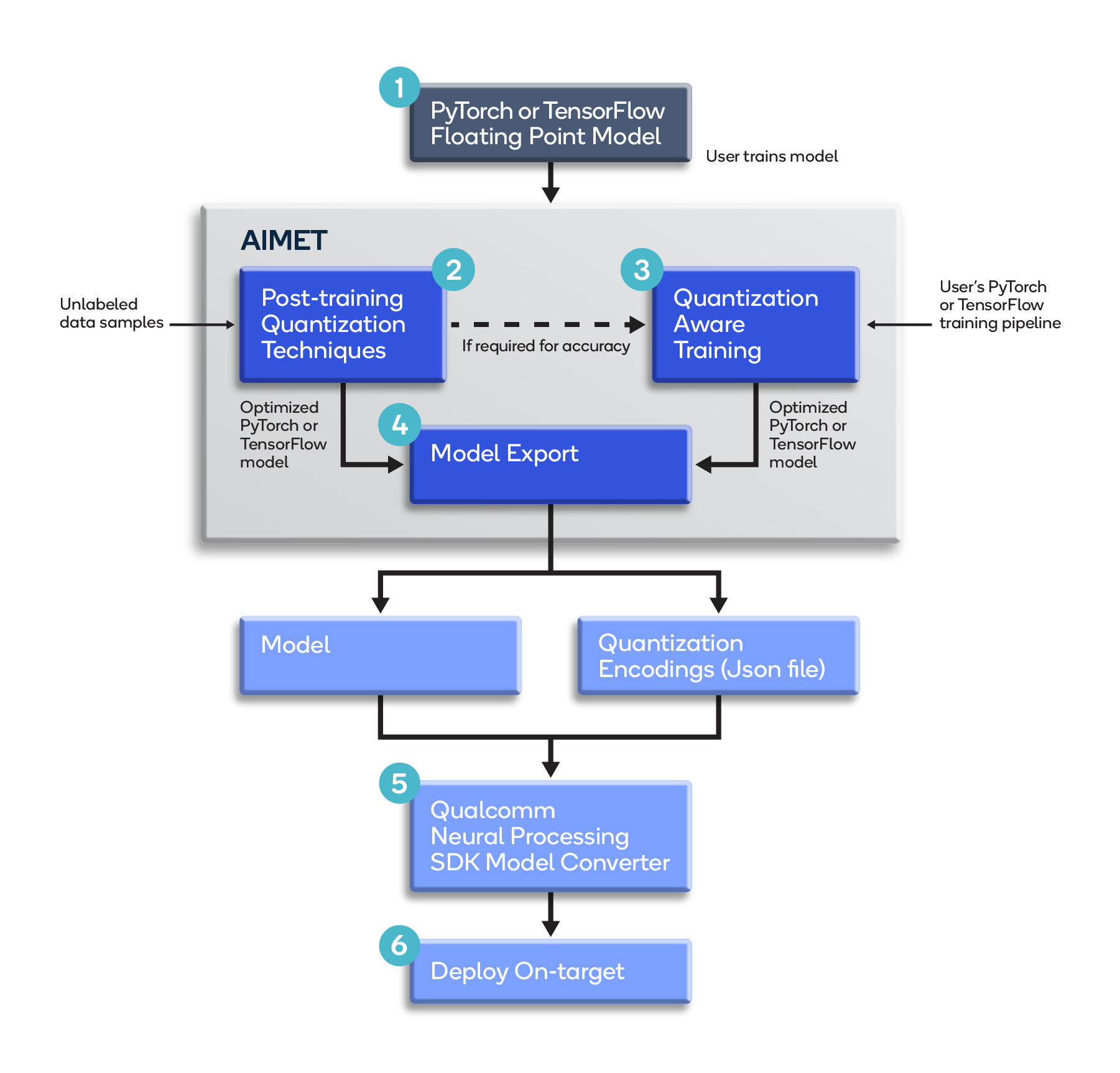
- The model is trained using PyTorch or TensorFlow with standard 32-bit floating-point (FP32) weights.
- The user optimizes the model for quantization using AIMET’s built-in post-training quantization techniques. Post-training techniques like Cross-Layer Equalization (CLE) and AdaRound can be used without labeled data and can provide good performance for several models without requiring model fine-tuning, thus avoiding the time and effort for hyper-parameter tuning and training. Using quantization simulation, AIMET evaluates model accuracy which gives an estimate of performance expected when running quantized inference on the target.
- The user (optionally) fine-tunes the model using AIMET’s Quantization-Aware Training feature to further improve quantization performance by simulating quantization noise and adapting model parameters to combat this noise.
- The optimized model is exported as a typical TensorFlow or PyTorch model, along with a JSON file containing recommended quantization encodings.
- The outputs from Step 4 are fed to the model conversion tool in the Qualcomm Neural Processing SDK. This converts the model to Qualcomm Technologies’ DLC format, using the quantization encodings generated by AIMET, for optimal execution on the SoC’s Qualcomm® AI Engine.
- The converted (DLC) model is deployed on the target hardware.
Snapdragon, Qualcomm Neural Processing SDK, and Qualcomm AI Engine are products of Qualcomm Technologies, Inc. and/or its subsidiaries.
AIMET is a product of Qualcomm Innovation Center, Inc.