Machine Learning on QCS610
Running inference workloads with heterogeneous computing
The Qualcomm® QCS610 is an SoC designed for low-power, on-device camera processing in use cases related to machine learning, edge computing, voice UI enablement, sensor processing and integrated wireless connectivity. It integrates the Qualcomm® Neural Processing SDK for AI and an image signal processor (ISP) with heterogeneous computing (CPU, GPU and DSP) architectures.
Use the SDK to accomplish the following:
- Execute different deep neural networks with supported layers.
- Write your own user-defined layer (UDL).
- Execute the neural network on the Qualcomm® Adreno™ GPU, Qualcomm® Kryo™ CPU, or Qualcomm® Hexagon™ DSP with the Hexagon Tensor Accelerator (HTA).
- Convert TensorFlow, Caffe, Caffe2, and ONNX models to a deep learning container (DLC) file using built-in tools for conversion.
- On the Hexagon DSP, quantize DLC files to 8-bit fixed-point.
- Debug and analyze neural network performance.
- Integrate a neural network into applications and other code via Java or C++.
| With this: | you can run these on the Qualcomm QCS610: |
|---|---|
| Neural Processing SDK for AI | TensorFlow, Caffe, ONNX models |
| Neural Network API | TFLite models |
| GStreamer plugin | DLC models |
| Gstreamer TFlite plugin | TFLite models |
This page covers:
- the development workflow and runtime workflow of the Neural Processing SDK for AI
- the conversion of different machine learning models to DLC files for execution on the DSP
- details on running a TensorFlow MobileNet Single-Shot multibox Detection (SSD) network on the QCS610 using the SDK and the GStreamer pipeline
Development workflow
- Develop a model and train it to meet the requirements of the application.
- Convert the model, with its static weights and biases, to the Deep Learning Container (DLC) format used by the SDK.
- To run inference on the Hexagon DSP, use the utility in the SDK to quantize and optimize the model.
- Develop machine learning applications with the Java or C++ API in the SDK to run the converted model on Qualcomm Technologies chipsets.
- If needed, use tools in the SDK to debug model performance and accuracy.
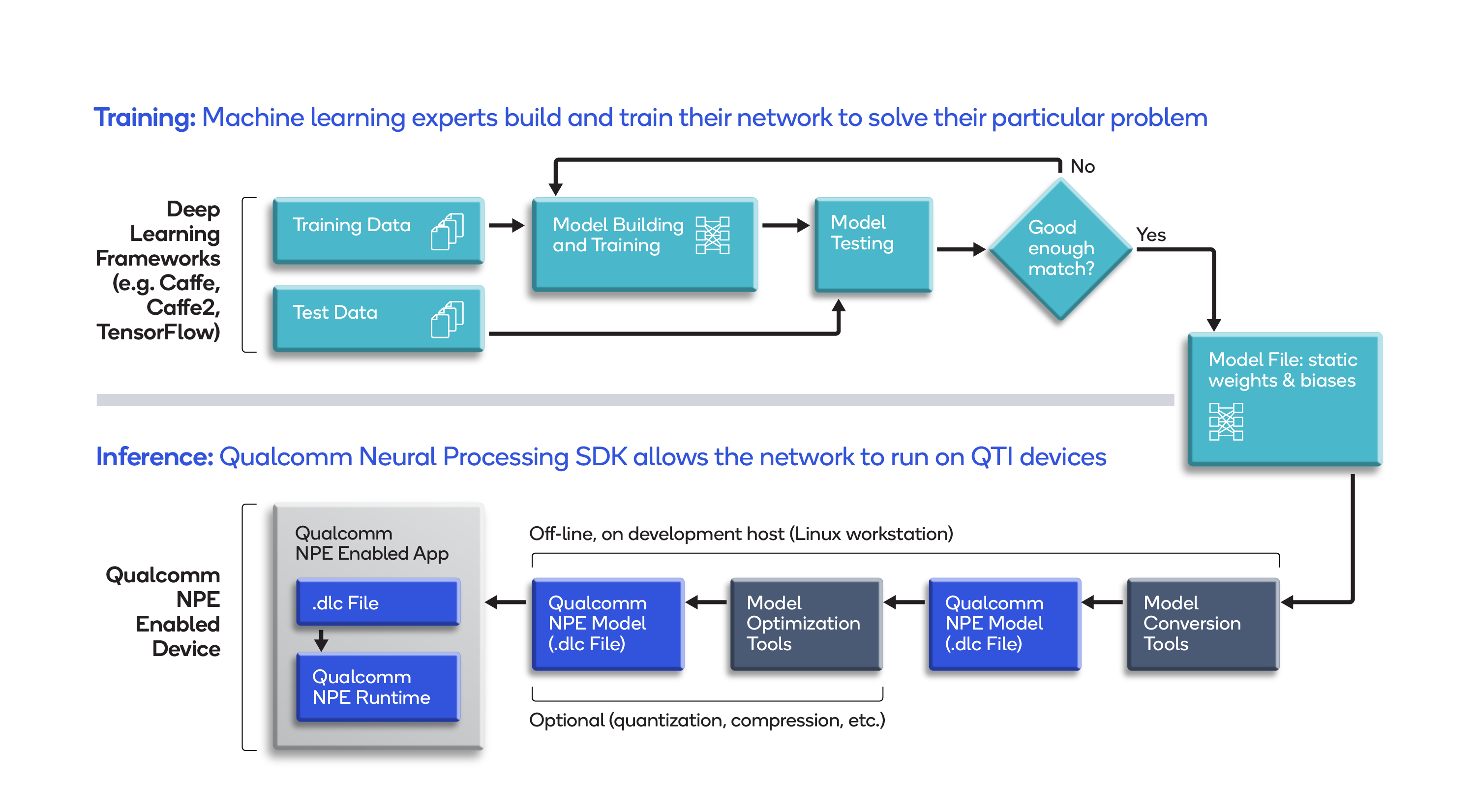
Runtime workflow
After converting and optimizing a model, you can use our Neural Processing SDK runtime to run it on the CPU, GPU and/or DSP of the Snapdragon® processor.
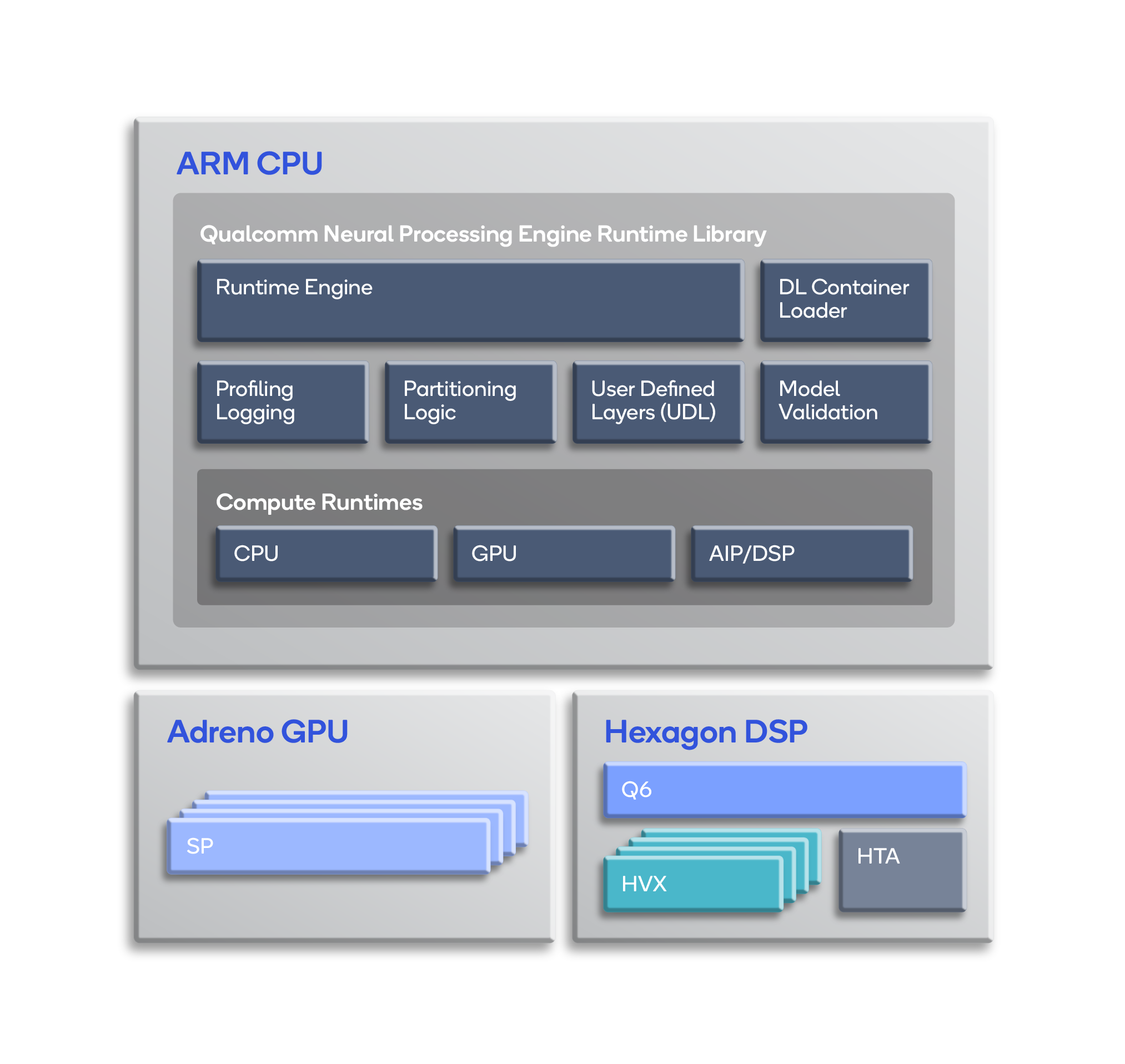
The main components of the runtime library are:
- DL Container Loader – Loads the DLC file created by one of the snpe-framework-to-dlc conversion tools.
- Model Validation – Validates that the loaded DLC file is supported by the required runtime.
- Runtime Engine – Executes a loaded model on the requested runtime(s) and gathers supporting user-defined layers (UDLs) and profiling information.
- Partitioning Logic – Processes the model including validation of layers for the required targets, and partitions the model into subnets based on the runtime target they are required to run on, if needed. For UDLs, the partitioner creates partitions such that the UDLs are executed on the CPU runtime. If CPU fallback is enabled, the partitioner partitions the model between layers that supported by the target runtime, and the rest that are to be executed on the CPU runtime (if they are supported).
- CPU Runtime – Runs the model on the Kryo CPU, which supports 32-bit floating-point or 8-bit quantized execution.
- GPU Runtime – Runs the model on the Adreno GPU, which supports hybrid or full 16-bit floating- point modes.
- DSP Runtime – Runs the model on the Hexagon DSP using Hexagon Vector Extensions (HVX), which are well suited to the vector operations commonly used by machine learning algorithms.
- AI Processor (AIP) Runtime - Runs the model on the Hexagon DSP using Hexagon NN, Q6 and Hexagon tensor accelerator (HTA).
Note: AIP is a runtime software abstraction of Q6, HVX and HTA into a single entity, controlling execution of a neural network model across all three hardware features.
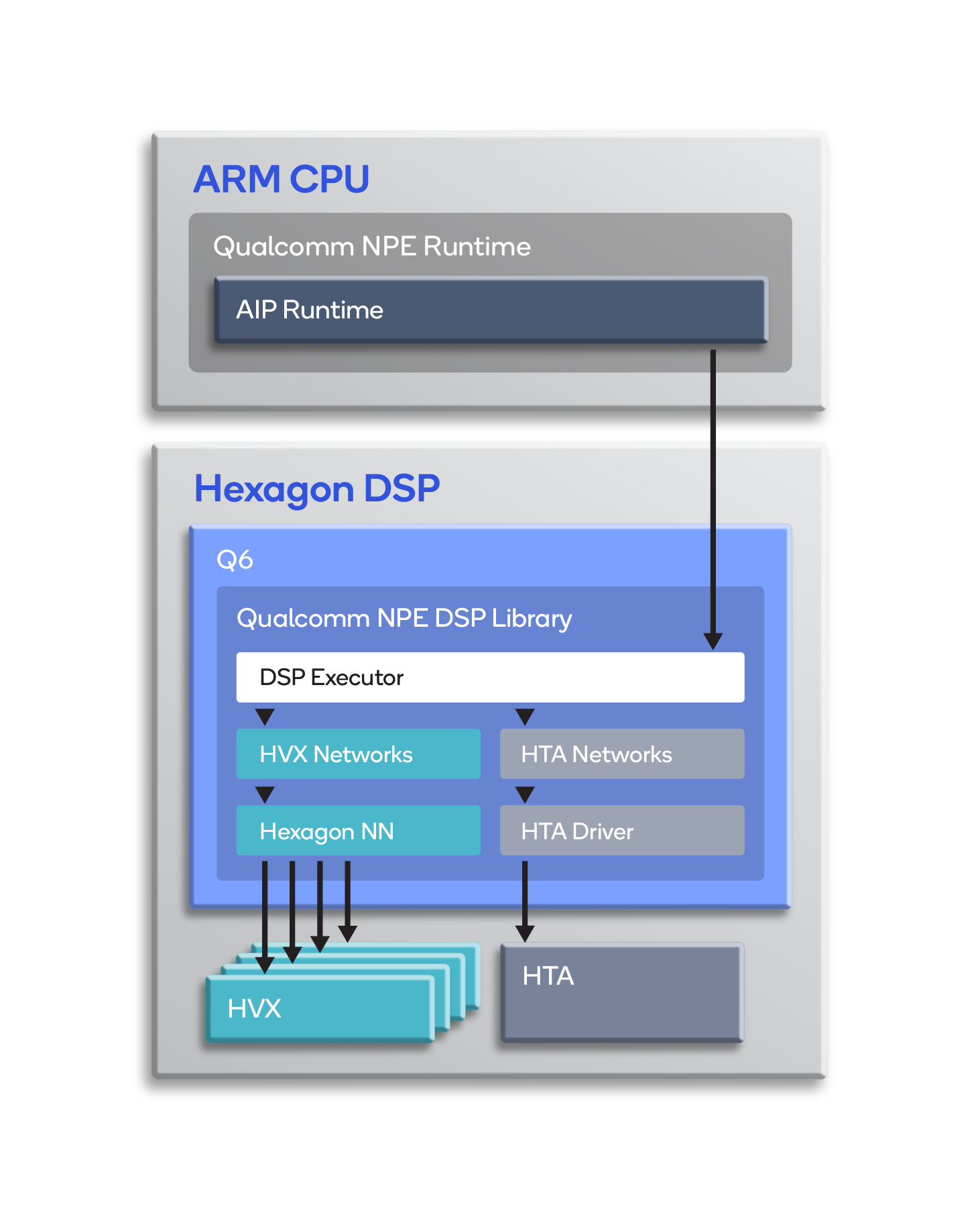
Executing on the Hexagon DSP
The SDK loads a library on the DSP that communicates with the AIP runtime. As shown below, the DSP library contains a DSP executor (to manage the execution of models across HTA and HVX), the HTA driver for running subnets on HTA, and Hexagon NN for running subnets using HVX.
The DSP executor uses a model description that also contains partitioning information. The description specifies which parts of the model will run on HTA and which on HVX. The partitioned parts are called “subnets.”
The DSP executor executes the subnets on the respective cores. It coordinates buffer exchanges, format conversions and dequantization as needed to return proper outputs to the Snapdragon runtime running on the ARM CPU.
Converting models to run on the QCS610 – TensorFlow example
The Qualcomm Neural Processing Engine SDK provides tools for converting models from Caffe/Caffe2, TensorFlow, TFLite and ONNX to DLC. The Getting Started page walks you through setting up the SDK.
The following steps show you how to convert a MobileNet v1 TensorFlow model to a .dlc file and run the .dlc on the QCS610.
Note: Before following this procedure, be sure to initialize the SDK environment (step 5 in “Setup the SDK”).
- The model should be a frozen graph, which the Qualcomm Neural Processing Engine SDK requires for conversion to .dlc. Run this command to convert the tensorflow model to a .dlc:
$ snpe-tensorflow-to-dlc --input_network mobilenet_v1.pb --input_dim input "1,224,224,3" --out_node "conv2d_110/BiasAdd" --output_path mobilenet_v1.dlc --allow_unconsumed_nodes - To run the converted .dlc model on the DSP, first quantize it as follows:
a. Generate preprocess raw image file.
b. Create the raw_img_path.txt file, then add the path to the generated raw image file inside raw_img_path.txt.
c. Run snpe-dlc-quantize to quantize the model:$ snpe-dlc-quantize --input_dlc mobilenet_v1.dlc --input_list raw_file.txt - Connect the host system to the QCS610 using a USB-C cable. Then, enter the following commands on the host system to push to the board the .dlc and raw image file created in the preceding steps:
$ adb shell mkdir /data/DLC
$ adb push mobilenet_v1.dlc /data/DLC
$ adb push mobilenet_v1_quantized.dlc /data/DLC
$ adb push image_224.raw /data/DLC
$ adb push raw_file.txt /data/DLC
$ adb shell - Check the throughput of the .dlc on different delegates using this command:
$ snpe-throughput-net-run --container mobilenet_v1.dlc --duration 15 --use_cpu --perf_profile "high_performance" --input_raw 224_img.rawNote: To run the model on a different core, replace --use_cpu with --use_gpu or --use_dsp. (To run on the DSP, specify --use_dsp and pass mobilenet_v1_quantized.dlc as a container.)
Note: snpe-dlc-quantize generates the quantized .dlc with the name <model_name>_quantized.dlc, even if --output_dlc is not passed as a parameter.
Using the GStreamer pipeline to run ML models
Besides using the SDK to run ML models on the Qualcomm QCS610, you can also use the GStreamer pipeline with suitable plugins to run models.
- Run a .dlc using GStreamer pipeline (qtimlesnpe plugin)
The GStreamer element quickly integrates a .dlc to available GStreamer plugins. The GStreamer plugin loads the .dlc; pre- and post-processes the video frames; configures the SDK to run on the CPU, GPU, DSP or HTA; and performs abstraction from the SDK.
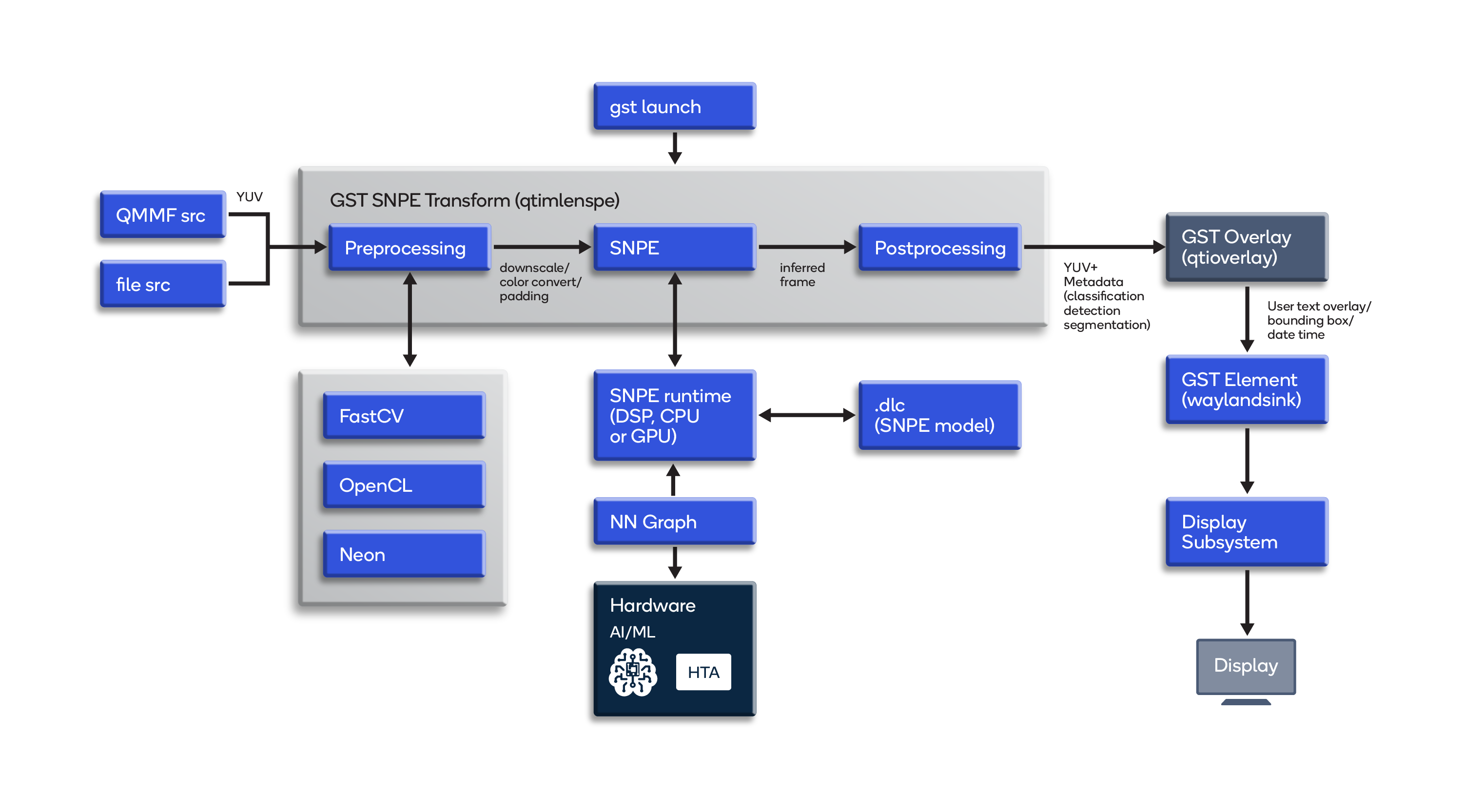
As shown in the diagram, upon launch the GStreamer pipeline delivers camera source or file source inference frames to the qtimlesnpe element along with a .dlc. The qtimlesnpe element uses the SDK to offload model computation to the requested runtime. In the qtimlesnpe element, inference results are gathered back for post-processing.
Use this GStreamer pipeline command to run a mobilenet model converted to a .dlc:/# gst-launch-1.0 -e qtiqmmfsrc ! video/x-raw, format=NV12, width=1280, height=720, framerate=30/1, camera=0 ! qtimlesnpe model=mobilenet_v1.dlc labels=labelmap.txt postprocessing=classification ! qtioverlay ! omxh264enc ! h264parse ! mp4mux ! filesink location=video.mp4 - Run a TFLite model using GStreamer pipeline (qtimletflite plugin)
To generate a TFlite file, a machine learning model is trained in TensorFlow, then frozen and converted to TFLite. Next, the model goes to the NNAPI runtime, which can offload models to the Hexagon DSP. For TFLite use cases, the GStreamer TFLite plugin can be used. The result from post-processing is given as machine learning metadata to the GStreamer buffer. Using NNAPI, the model can be accelerated by developing an application directly.
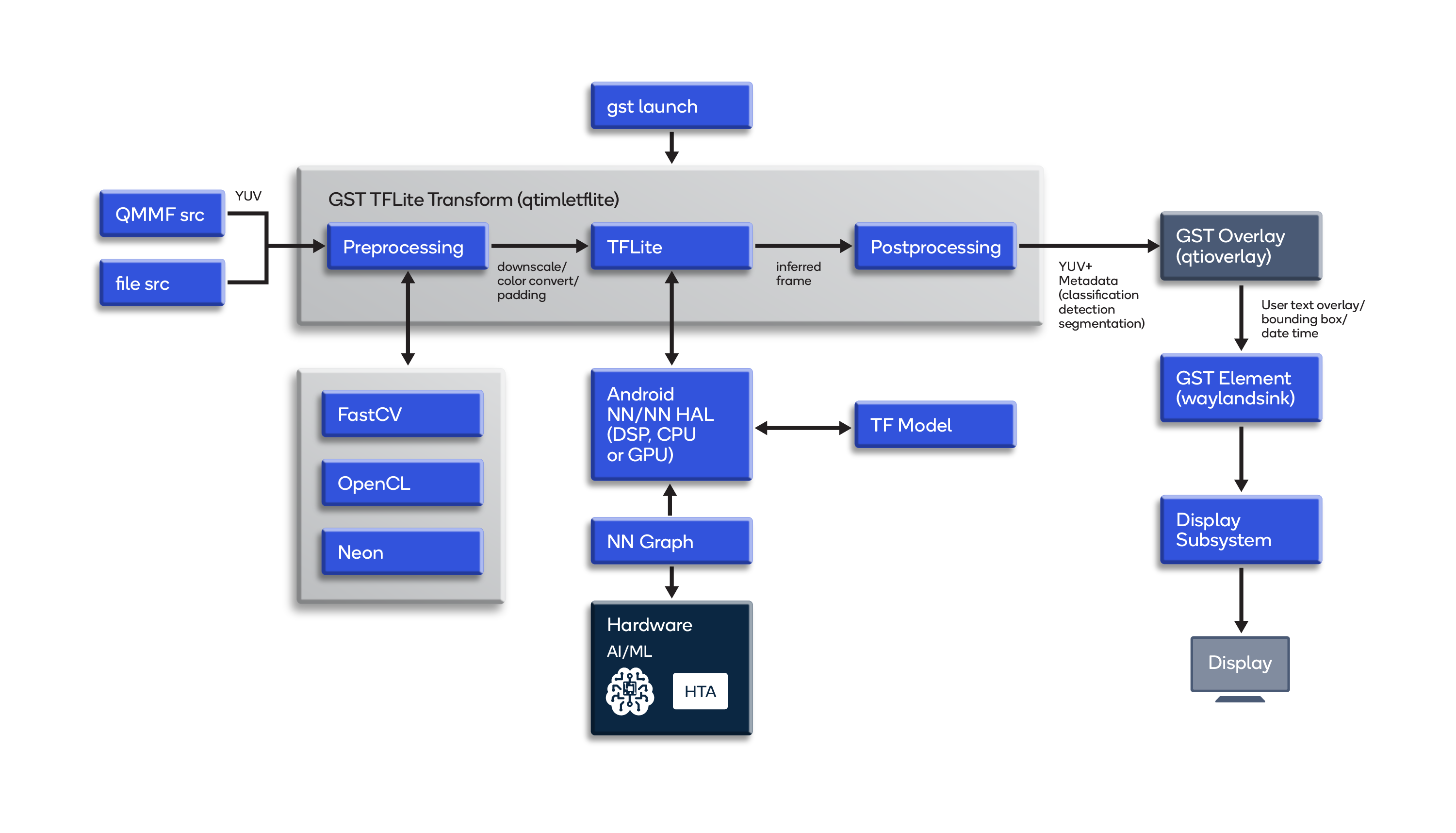
As shown in the diagram, upon launch inference frames from either a camera source or a file source are delivered to qtimletflite, the GStreamer TFLite plugin. The TFLite runtime can be running on the CPU, DSP or GPU. The models are appropriated for TF on a separate host. For post-processing, inference results are gathered back in the GStreamer TFLite plugin.
Use this GStreamer pipeline command to run a TFLite converted mobilenet model:#/ gst-launch-1.0 -e qtiqmmfsrc ! video/x-raw, format=NV12, width=1280, height=720, framerate=30/1, camera=0 ! qtimletflite model=mobilenet_v1.tflite labels=labelmap.txt postprocessing=classification ! qtioverlay ! omxh264enc ! h264parse ! mp4mux ! filesink location=video.mp4The qtimletflite plugin makes use of NNAPI, an Android C API designed to accelerate TFLite models on the CPU, GPU and Hexagon DSP of Android devices.
For more context and information, consult these related pages:
- https://developer.qualcomm.com/docs/snpe/overview.html
- https://developer.qualcomm.com/software/qualcomm-neural-processing-sdk
- https://developer.qualcomm.com/docs/snpe/snapdragon_npe_runtime.html
- https://developer.qualcomm.com/docs/snpe/aip_runtime.html
- https://developer.qualcomm.com/qualcomm-robotics-rb5-kit/software-reference-manual/machine-learning/snpe
- https://developer.android.com/ndk/guides/neuralnetworks
- https://developer.qualcomm.com/qualcomm-robotics-rb5-kit/software-reference-manual/machine-learning/tensorflow
Qualcomm QCS610, Qualcomm Kryo, Qualcomm Adreno, Qualcomm Hexagon, Snapdragon and Qualcomm Neural Processing SDK are products of Qualcomm Technologies, Inc. and/or its subsidiaries.