Snapdragon and Qualcomm branded products are products of
Qualcomm Technologies, Inc. and/or its subsidiaries.
What do you do when your always-on application needs image processing, computer vision or machine learning, but it keeps maxing out the CPU and causing cores to shut down from thermal throttling?
“Must be time to look at parallel processing and heterogeneous computing,” you say, “and maybe offload some of that work from CPU to GPU and DSP.”
Good idea. Why limit your compute-intensive tasks when you can run them on the GPU, DSP and other devices and manage them from host code running on the CPU?
But I hear most developers talk about parallelism and heterogeneous programming in one of three ways:
- They’ve always written serially for CPU and don’t know how to push work to other cores (beginning).
- They know how to process images and algorithms heterogeneously, but they want to do it more efficiently (experienced).
- They understand heterogeneous programming, but they want more control over the dynamic distribution of workloads (expert).
The Qualcomm® Symphony SDK has tools for all three levels of heterogeneous programming. Available for download now from the Qualcomm Developer Network, Symphony SDK is a product of Qualcomm Technologies, Inc. (QTI) designed to simplify heterogeneous programming on Snapdragon processors.
What is the Symphony SDK?
Most developers know when their app has maxed out the CPU, but they don’t usually know the overall system state well enough to take advantage of heterogeneous computing. The parallelism and heterogeneous computing you get with Symphony can be your path to fully utilizing the Snapdragon system on a chip (SoC) and getting the same or better performance with lower power consumption.
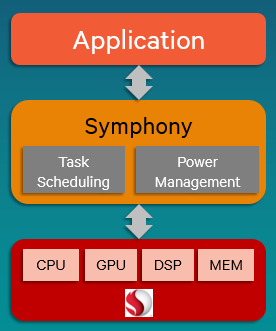
Here’s what’s inside the Symphony SDK:
- Symphony SDK – The SDK provides C++ APIs for parallelizing and assigning tasks to the Symphony runtime. Its user-level library runs on Android devices and allows application prototyping on x86 Linux and Windows. It includes C++ APIs for lowering power consumption; affinity APIs for requesting which CPU cores should execute tasks; a scheduler framework to target the CPU, GPU and DSP; interfaces for communicating with the Symphony runtime; documentation and sample applications.
- Symphony runtime – Decision-making runtime software handles overall system scheduling and power management.
How can I Use the Symphony SDK to Reduce Power Consumption and Thermal Profile?
The SDK is designed to meet developer needs at all three levels:
BeginningThe fastest way to build a Symphony application is by using predefined Symphony building blocks, called patterns. If your parallel algorithm matches one of the parallel programming patterns in Symphony, then you can use the pattern directly. In the following example, a simple substitution of the symphony::pfor_each pattern parallelizes a for-loop that processes elements in a collection:

On the simplest level, that example applies to developers who want to use more CPU cores because they are maxing out the CPU, or who want to use the CPU in a way that doesn’t cause overheating.
ExperiencedAt the experienced level, developers want to use the GPU and DSP much more effectively and manage the power state better. Beyond parallelized for-loops, big.LITTLE affinity is important for allocating tasks appropriately among big, power-intensive cores and little, power-efficient cores.
Consider an always-on, H.264-like video encoding algorithm. It is implemented as a soft encoder (4 big and 4 LITTLE CPU cores) with a target frame rate of 30 fps at 1080p. The hardware is capable of delivering almost 40 fps in bursts using all 8 cores, but recurring thermal alarms cause cores and frequencies to ramp down and back up constantly, resulting in a moving average of less than 20 fps. The encoder would not be thermally sustainable in a long-running application like video surveillance or driving.
By invoking big.LITTLE affinity through the Symphony SDK, as shown below, the algorithm can encode with 2 big and 4 LITTLE cores:
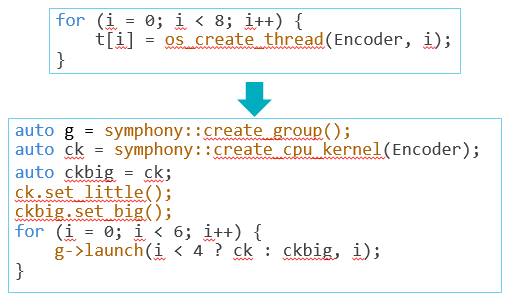
The encoder is designed to avoid thermal alarms and comfortably deliver 30 fps at 1080p on the same hardware.
ExpertEven for programmers well versed in heterogeneous computing, Symphony is engineered to simplify work by managing the power states dynamically and distributing work on the basis of constantly changing system state: for example, the number of cores currently active, the workload pending on the CPU, GPU and DSP devices, and the power/frequency states of the devices. In far less code than it would take if developers wrote it themselves, the sample below shows how Symphony can offer power control over frequencies and flexibility in moving data and computation to any device (CPU, GPU, DSP):

- The native APIs for GPU (green) and DSP (red) differ from each other considerably and are more complex to use.
- All data synchronization must be explicit.
- All the optimizations – such as the use of AHP versus UHP, and the use of the OpenCL calls MapBuffer versus ReadBuffer – are hard-coded in the application code, even though the optimal choice for these calls may vary across devices. In particular, the GPU and DSP synchronize data with minimal data transfer costs if ION memory is used. The native code shown above requires arcane, device-specific calls to properly allocate ION memory and use it for buf_c.
In contrast, Symphony is designed to automate these optimizations based on the task graph and some high-level hints, as shown below:

- Symphony can make it easy to set device frequencies for various devices (gold). Native APIs, such as writes to Android/Linux sysfs nodes, may differ across platforms and may not always permit a user-space application to modify frequencies.
- Symphony tasks have a uniform syntax (blue) across devices. Data is designed to be synchronized across devices optimally, minimizing allocation of memory and data copies. For example, buf_c moves results between the GPU and DSP tasks. Internally Symphony is free to choose the most efficient mechanism for allocating memory for buf_c, such as the use of ION memory.
- Symphony can make it easy to use up all dynamically available CPU parallelism, such as with the pfor_each construct. In contrast, the Native API code could have created its own multiple threads to use multiple cores or it could have used an existing thread pool. Either choice could incur greater overhead and force the user to commit to a fixed thread count, without taking advantage of the number of cores dynamically free at that moment.
As you push more compute-intensive tasks onto mobile processors, you start to realize that parallelism and heterogeneous computing can relieve hot spots and thermal problems in your apps. Symphony is designed to use less power and lower frequencies for the same or better performance. It matches the instruction set architecture (ISA) of the GPU, DSP and other cores to the specific nature of the work and it matches the device power states to the work.
Next Steps
Download the Symphony SDK now, then have a look at the sample apps. There’s something in the SDK for beginning, experienced and expert developers alike. In the documentation you’ll find a Getting Started guide, tutorials on parallel processing and image processing, and the interface specification. (If you want the live code from the listings in this blog post, let me know in the comments below.)
Also use Snapdragon® Profiler to analyze CPU, GPU, DSP, memory, power, thermal and network data about your app.
Best of all, there is no additional licensing fee for using these SDKs and tools. You have virtually nothing to lose but your thermal issues and performance bottlenecks.
Comments
Re: Heterogeneous Computing Made Simpler with Symphony SDK