Parallel variant
Accelerating with the Snapdragon Heterogeneous Compute SDK
Given the runtime characteristics of the algorithm, what can be parallelized to lower power consumption?
The for-loop runs through all N numbers, and can be parallelized with a pattern from the Snapdragon® Heterogeneous Compute SDK. The highlighted code below shows the for-loop replaced by pfor_each:
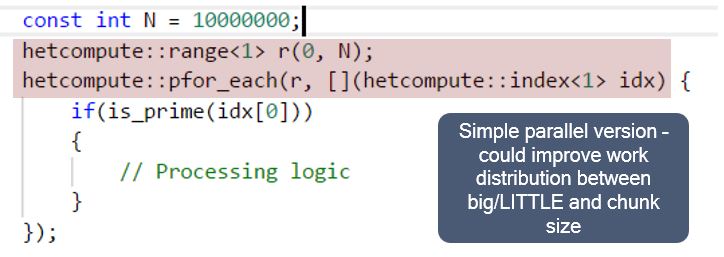
The first highlighted line shows an abstraction provided by the Snapdragon Heterogeneous Compute SDK: a simple object that keeps track of the start (0) and end (N=10,000,000 integers) range. The second highlighted line replaces the sequential for-loop, with pfor_each giving the range and a lambda that is similar to the function that checks for prime numbers. (Incidentally, this pfor_each version could be further optimized with some of the pattern tuners for a virtual distribution between the big and LITTLE clusters.)
Once the changes are made, Snapdragon Profiler again reveals how the algorithm behaves in the system.
First of all, the real-time metrics show that, instead of one CPU core at a time, all eight cores — big and LITTLE — are engaged in parallel:
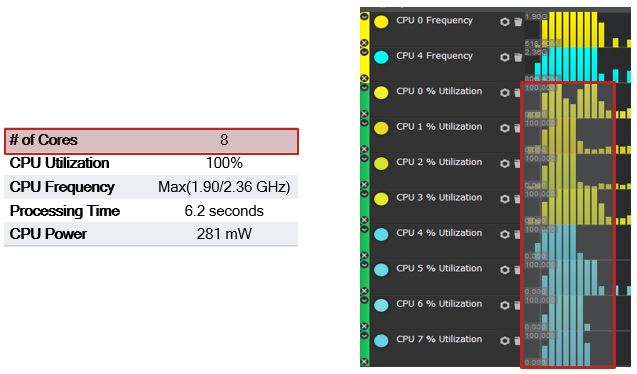
Furthermore, all eight cores are utilized at 100 percent of capacity when the algorithm runs:

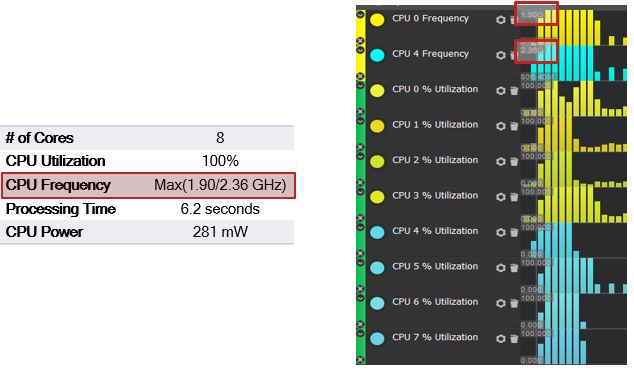
CPU Frequency is at its maximum in both clusters — 1.9 GHz for the LITTLE cluster and 2.36 GHz for the big cluster:
Parallelization has shortened processing time by more than 80 percent — from 34 seconds to 6.2 seconds:
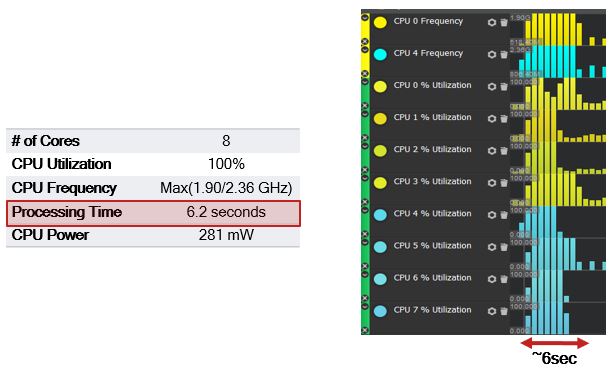
However, parallelization has caused the CPU to consume more than double the power — from 125 mW to 281 mW. Thus, the Snapdragon Heterogeneous Compute SDK has provided the best performance possible with this algorithm. The next step is to balance that against power consumption using the Snapdragon Power Optimization SDK.