Qualcomm® Kryo™ CPU
Overview
Kryo CPUs are ARM-based big.LITTLE architecture. To optimize CPU utilization, we recommend looking at the Qualcomm Products and/or the Device Finder to identify the families of Kryo CPU chipsets you would like to target and which ARM Cortex CPU is it based on. For example, Qualcomm Snapdragon 865 has the Kryo 585 CPU which is based on the Cortex-A77.
ARM has family specific software optimization guides that provide details on how to optimize applications for those CPUs.
big.LITTLE
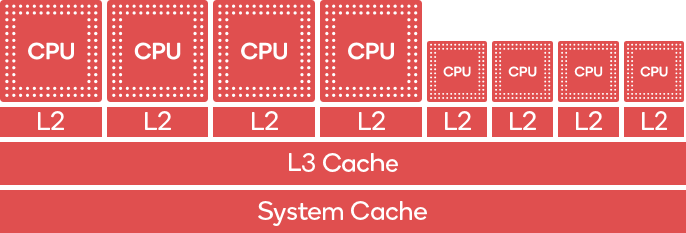
big.LITTLE architecture is composed of big cores which are optimized for performance and little cores optimized for power efficiency. Understanding this distinction and how to work with this architecture is crucial to optimizing performance and power efficiency, which reflects on longer play sessions and the thermal profile of the game.
For additional information on big.LITTLE architecture visit https://www.arm.com/why-arm/technologies/big-little. To understand how to take advantage of thread placement on your game, refer to Controlling Task Execution.
Understanding CPU utilization
Measuring CPU Utilization of a game can be more nuanced than measuring GPU Utilization. Being ‘CPU bound’ does not necessarily mean the CPU is fully utilized. An important aspect of game development is understanding the threaded nature of the game and game engine.
Several games and engines are single or dual threaded by maintaining a main thread and a render thread at a minimum. It is worth noting that when a game relies heavily on these threads to do all the work, the game can be bottlenecked by a single thread on a single core and become CPU bound.
On Snapdragon Profiler and an 8 core CPU platform, you might encounter a CPU Utilization metric reporting ~12.5% (100% / 8 Cores). This might not raise any flags on the source of the bottleneck for this game.
The following example game demo illustrates this scenario:

Using Snapdragon Profiler’s CPU Utilization Realtime metric does not raise any flags that indicate that the CPU is the bottleneck. Upon closer inspection, using Trace mode reveals one thread is fully utilized and almost all other cores are idle most of the time.

Controlling Task Execution
Task scheduling on Kryo CPUs is performed at the hardware level. This scheduling can be guided by the OS through platform APIs that allow game developers to provide “hints” to the system to control and balance power and performance. On Snapdragon platforms, these hints are provided via the Heterogeneous Compute SDK which, among other useful APIs, provides developers the ability to control task execution and peg tasks to a desired core or core type.
LITTLE cores should be leveraged as much as possible. Given a frame budget of 16ms (60FPS) a developer can identify tasks using tools such as Snapdragon Profiler that would be good candidates to be moved to little cores.
For example, a game with a cloth simulation solver that takes 3ms to execute on a big core may take 10ms on a little core. As long as this execution time is acceptable (which in this case it is because our budget is 16ms), this task can and should be moved to the little cores. This will alleviate utilization of big cores and be more power efficient.
Power considerations
Another area to watch for is excessive or unnecessary wakeups of idle cores, which can result in more power consumption. One solution is to pack tasks on to the same core while trying not to overload a core. Fortunately, runtimes for big.LITTLE platforms, such as those in Snapdragon mobile platforms, are engineered to employ three common task scheduling methods to help take care of such issues for you:
Core clustering: Cores of the same size are treated as one cluster. The most appropriate cluster is chosen based on system demands. ** This can be efficient if the whole cluster migrates to the big core. However, this is less optimal than the following two methods because the CPU frequency driver tells the OS kernel the required frequency and voltage.
In-kernel switching or CPU migration: A big and a little core are paired into a virtual core in which only one of the two physical cores in that virtual core is used (demand dependent). ** This provides increased efficiency over core clustering, but requires that core capabilities are the same.
Global task scheduling: All physical cores are available all of the time. The global task scheduler allocates tasks on a per-core basis depending on demands. ** This is the optimal method because the OS scheduler can allocate work on any core, all cores, or any combination, while unused cores are automatically turned off. ** This method does not require matching core configurations. It can react more quickly to load changes, and work can be allocated at a finer level of granularity than by the CPU frequency driver used in core clustering.
Developers also have the ability to control power modes on Snapdragon platforms via the Power Optimization SDK. This SDK allows developers to adjust the power mode based on the game or task use case and performance/power demands with the following modes:
Efficient mode: Achieves close-to-best performance with power savings.
Performance burst mode: Supports all cores at the maximum frequency for a short duration of time. It is useful for bursts of intensive computation to gain performance.
Saver mode: Provides around half of the peak performance of the system and helps when performance requirements of the application are small.
Window mode: Allows for fine tuning of performance/power balance using arguments to set the minimum and maximum frequency percentages relative to the maximum frequency that cores can use.
Normal mode: Returns system to its default state.
NEON intrinsics
Arm Neon is an advanced SIMD architecture for ARM processors. The NEON instruction set makes a bank of specialized registers available for SIMD processing.
The instruction set includes typical SIMD operations for moving data between Neon and general purpose registers, as well as data processing and type conversion. Effective use of Neon through hand-coded assembly, intrinsic functions, or automatic vectorization by the compiler can lead to tremendous performance gains for multimedia applications. Qualcomm’s SIMD/FPU co-processor is compliant with the Arm Neon instruction set.
For more information on Neon intrinsics, refer to https://developer.arm.com/architectures/instruction-sets/simd-isas/neon.
Best practices
Avoid single-thread 100% CPU Utilization bottleneck
Pay close attention to the threaded nature of your game and task system to avoid bottlenecking a single core with a thread while most other cores are idle or under-utilized.
Tools such as Snapdragon Profiler can help identify problematic areas using the Android Trace User Markers for instrumentation, or Snapdragon Profiler Sampling mode, which can generate a flamegraph of the most utilized functions across all cores.
Avoid disk I/O or blocking operations on main/render threads
Overusing main/render threads on Android can be problematic and can lead to ‘Application Not Responding’ (ANR) errors – especially when using disk I/O or blocking operations.
For more information on ANRs in Android refer to, ANRs.
Use Neon for SIMD operations
When possible, use Neon intrinsics. If you are using a third party game engine or middleware, check for Neon optimizations and enable them when possible.
Use big cores for compute intensive tasks
When a task requires a large amount of compute work, it is preferrable to use big cores. This can help alleviate bottlenecks on a single core and maintain a more consistent FPS.
Use little cores for power efficient tasks
As described in Controlling Task Execution, running most of the game’s logic on little cores can lead to greater power benefits and better battery life, lower temperature, and prolonged gaming sessions by users.
Multi-thread game initialization
Game loading can be memory and compute intensive, which can lead to long wait times for end-users. Using multiple threads to distribute game loading can result in decreased load time and improve user experience.