Overview
The benchmark shipped in the SNPE SDK consists of a set of python scripts that runs a network on a target Android/LinuxEmbedded device and collect performance metrics. It uses executables and libraries found in the SDK package to run a DLC file on target, using a set of inputs for the network, and a file that points to that set of inputs.
The input to the benchmark scripts is a configuration file in JSON format. The SDK ships with a configuration file for running the AlexNet model that is created in the SNPE SDK. SDK users are encouraged to create their own configuration files and use the benchmark scripts to run on target to collect timing and memory consumption measurements.
The configuration file allows the user to specify:
- Name of the benchmark (i.e., AlexNet)
- Host path to use for storing results
- Device paths to use (where to push the necessary files for running the benchmark)
- Device to run the benchmark on (only one device is supported per run)
- Hostname/IP of remote machine to which devices are connected
- Number of times to repeat the run
- Model specifics (name, location of dlc, location of inputs)
- SNPE runtime configuration(s) to use (combination of CPU, GPU, GPU_FP16 and DSP)
- Which measurements to take ("mem" and/or "timing")
- Profiling level of measurements ("off", "basic", "moderate" or "detailed")
Command Line Parameters
To see all of the command line parameters use the "-h" option when running snpe_bench.py
usage: snpe_bench.py [-h] -c CONFIG_FILE [-o OUTPUT_BASE_DIR_OVERRIDE]
[-v DEVICE_ID_OVERRIDE] [-r HOST_NAME] [-a]
[-t DEVICE_OS_TYPE_OVERRIDE] [-d] [-s SLEEP]
[-b USERBUFFER_MODE] [-p PERFPROFILE] [-l PROFILINGLEVEL]
[-json] [-cache]
Run the snpe_bench
required arguments:
-c CONFIG_FILE, --config_file CONFIG_FILE
Path to a valid config file
Refer to sample config file config_help.json for more
detail on how to fill params in config file
optional arguments:
-o OUTPUT_BASE_DIR_OVERRIDE, --output_base_dir_override OUTPUT_BASE_DIR_OVERRIDE
Sets the output base directory.
-v DEVICE_ID_OVERRIDE, --device_id_override DEVICE_ID_OVERRIDE
Use this device ID instead of the one supplied in config
file. Cannot be used with -a
-r HOST_NAME, --host_name HOST_NAME
Hostname/IP of remote machine to which devices are
connected.
-a, --run_on_all_connected_devices_override
Runs on all connected devices, currently only support 1.
Cannot be used with -v
-t DEVICE_OS_TYPE_OVERRIDE, --device_os_type_override DEVICE_OS_TYPE_OVERRIDE
Specify the target OS type, valid options are
['android', 'android-aarch64',
'le_oe_gcc8.2', 'le64_oe_gcc8.2']
-d, --debug Set to turn on debug log
-s SLEEP, --sleep SLEEP
Set number of seconds to sleep between runs e.g. 20
seconds
-b USERBUFFER_MODE, --userbuffer_mode USERBUFFER_MODE
[EXPERIMENTAL] Enable user buffer mode, default to
float, can be tf8exact0
-p PERFPROFILE, --perfprofile PERFPROFILE
Set the benchmark operating mode (balanced, default,
sustained_high_performance, high_performance,
power_saver, system_settings)
-l PROFILINGLEVEL, --profilinglevel PROFILINGLEVEL
Set the profiling level mode (off, basic, moderate, detailed).
Default is basic.
-json, --generate_json
Set to produce json output.
-cache, --enable_init_cache
Enable init caching mode to accelerate the network
building process. Defaults to disable.Running the Benchmark
Prerequisites
- The SNPE SDK has been set up following the SNPE Setup chapter.
- The Tutorials Setup has been completed.
- Optional: If the device is connected to remote machine, the remote adb server setup needs to be done by the user.
Running AlexNet that is Shipped with the SDK
snpe_bench.py is the main benchmark script to measure and report performance statistics. Here is how to use it with the AlexNet model and data that is created in the SDK.
cd $SNPE_ROOT/benchmarks
python3 snpe_bench.py -c alexnet_sample.json -a
where
-a benchmarks on the device connected
Viewing the Results (csv File or json File)
All results are stored in the "HostResultDir" that is specified in the configuration json file. The benchmark creates time-stamped directories for each benchmark run. All timing results are stored in microseconds.
For your convenience, a "latest_results" link is created that always points to the most recent run.
# In alexnet_sample.json, "HostResultDir" is set to "alexnet/results" cd $SNPE_ROOT/benchmarks/alexnet/results # Notice the time stamped directories and the "latest_results" link. cd $SNPE_ROOT/benchmarks/alexnet/results/latest_results # Notice the .csv file, open this file in a csv viewer (Excel, LibreOffice Calc) # Notice the .json file, open the file with any text editor
CSV Benchmark Results File
The CSV file contains results similar to the example below. Some measurements may not be apparent in the CSV file. To get all timing information, profiling level needs to be set to detailed. By default, profiling level is basic. Note that colored headings have been added for clarity.
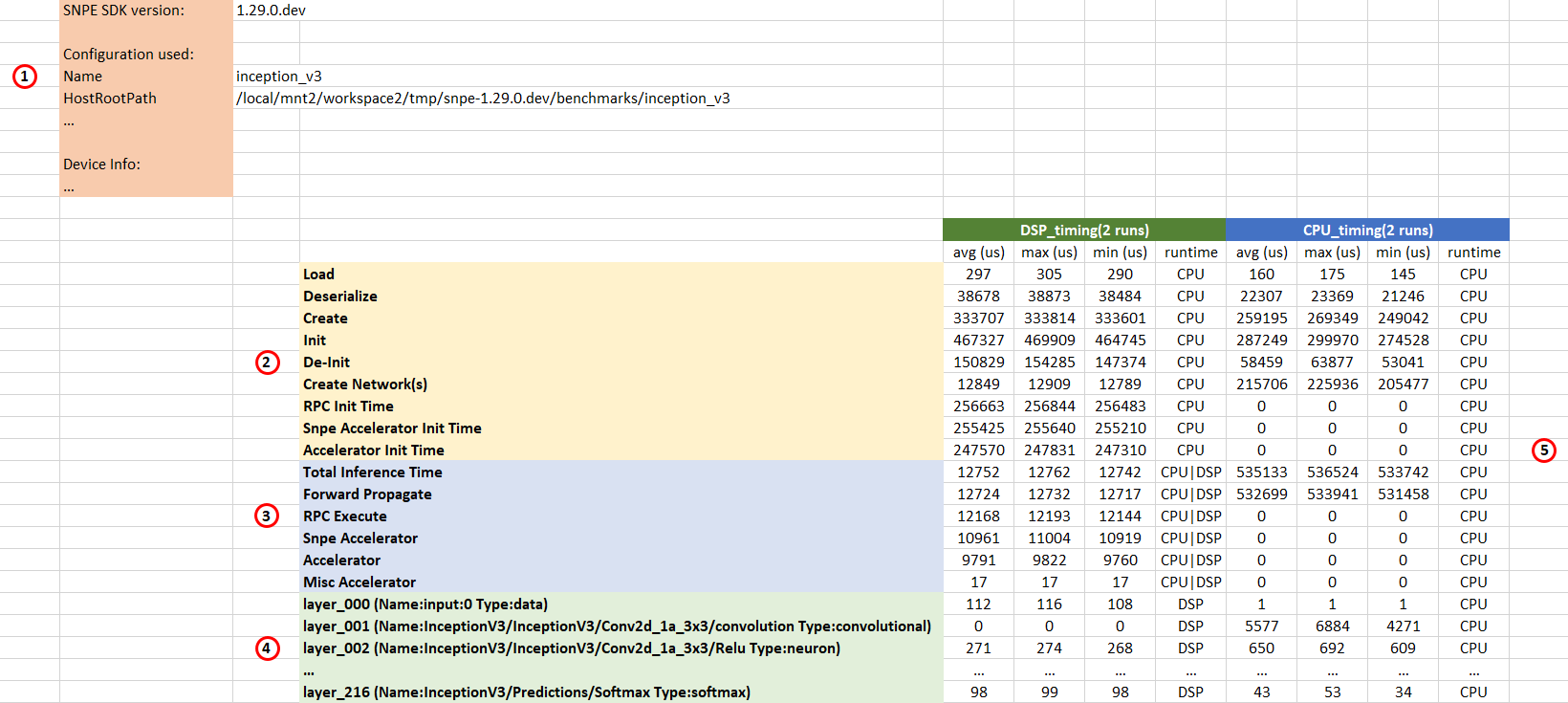
CSV 1: Configuration
This section contains information about:
- the SDK version used to generate the benchmark run
- model name and path to the DLC file
- runtimes selected for the benchmark
- etc.
CSV 2: Initialization metrics
This section contains measurements concerning model initialization. Profiling level affects the amount of measurements collected. No metrics are collected for profiling off. Metrics for basic and detailed are shown below.
Profiling level: Basic
- Load measures the time required to load the model's metadata.
- Deserialize measures the time required to deserialize the model's buffers.
- Create measures the time spent to create SNPE network(s) and initialize all layers for the given model. Detailed breakdown of create time can be retrieved with profiling level set to detailed.
- Init measures the time taken to build and configure SNPE. This time includes time measured Load, Deserialize, and Create.
- De-Init measures the time taken to de-initialized SNPE.
Profiling level: Moderate or Detailed
- Load measures the time required to load the model's metadata.
- Deserialize measures the time required to deserialize the model's buffers.
- Create measures the time spent to create SNPE network(s) and initialize all layers for the given model. Detailed breakdown of create time can be retrieved with profiling level set to detailed.
- Init measures the time taken to build and configure SNPE. This time includes time measured Load, Deserialize, and Create.
- De-Init measures the time taken to de-initialized SNPE.
- Create Network(s) measures the total time required to create all network(s) for the model. Models that are partitioned will result in multiple networks being created.
- RPC Init Time measures the entire time spent on RPC and accelerators used by SNPE. This time includes time measured in Snpe Accelerator Init Time and Accelerator Init Time. Currently only available for DSP and AIP runtime. Will appear as 0 for other runtimes.
- Snpe Accelerator Init Time measures the total time spent by SNPE to prepare the data for the accelerator process such as GPU, DSP, AIP. Currently only available for DSP and AIP runtime. Will appear as 0 for other runtimes.
- Accelerator Init Time measures the total processing time spent on the accelerator core, which may include different hardware resources. Currently only available for DSP and AIP runtime. Will appear as 0 for other runtimes.
CSV 3: Execution metrics
This section contains measurements concerning the execution of one inference pass of the neural network model. Profiling level affects the amount of measurements collected.
Profiling level: Basic
- Total Inference Time measures the entire execution time of one inference pass. This includes any input and output processing, copying of data, etc. This is measured at the start and end of the execute call.
Profiling level: Moderate or Detailed
- Total Inference Time measures the entire execution time of one inference pass. This includes any input and output processing, copying of data, etc. This is measured at the start and end of the execute call.
- Forward Propogate measures the time spent executing one inference pass excluding processing overheads on one of the accelerator cores. For example, in the case of the GPU this represents the execution time of all the GPU kernels running on the GPU HW.
- RPC Execute measures the entire time spent on RPC and accelerators used by SNPE. This time includes time measured in Snpe Accelerator and Accelerator. Currently only available for DSP and AIP runtime. Will appear as 0 for other runtimes.
- Snpe Accelerator measures the total time spent by SNPE to setup processing for the accelerator. Currently only available for DSP and AIP runtime. Will appear as 0 for other runtimes.
- Accelerator measures the total execution time spent on the accelerator core, which may include different hardware resources. Currently only available for DSP and AIP runtime. Will appear as 0 for other runtimes.
Profiling level: Detailed
- Misc Accelerator measures the total execution time spent on the accelerator core for optimization elements not specified by SNPE. For example, in the case of DSP this represents the exection time spent on additional layers added by the accelerator to acheive optimal performance. Currently only available for DSP and AIP runtime. Will appear as 0 for other runtimes.
CSV 4: Model Layer Names
This section contains the list of names of each layer of the neural network model.
Note that this information will only be present for DSP/GPU runtime only if the profiling level is set to detailed.
CSV 5: Model Layer Times
Each row in this section represents the execution time of each layer of the neural network model. For each runtime the average, min and max values are represented. Note that the values corresponding to each layer are referring to cycle counts, whereas the values for all other components like init, ForwardPropagate are in microseconds.
Note that this information will only be present for DSP/GPU runtime only if the profiling level is set to detailed.
Refer to Measurement Methodology Measurement Methodology for more background on the numbers.
JSON Benchmark Results File
The benchmark results published in the CSV file can also be made available in JSON format. The contents are the same as in the CSV file, structured as key-value pairs, and will help parsing the results in a simple and efficient manner. The JSON file contains results similar to the example below.
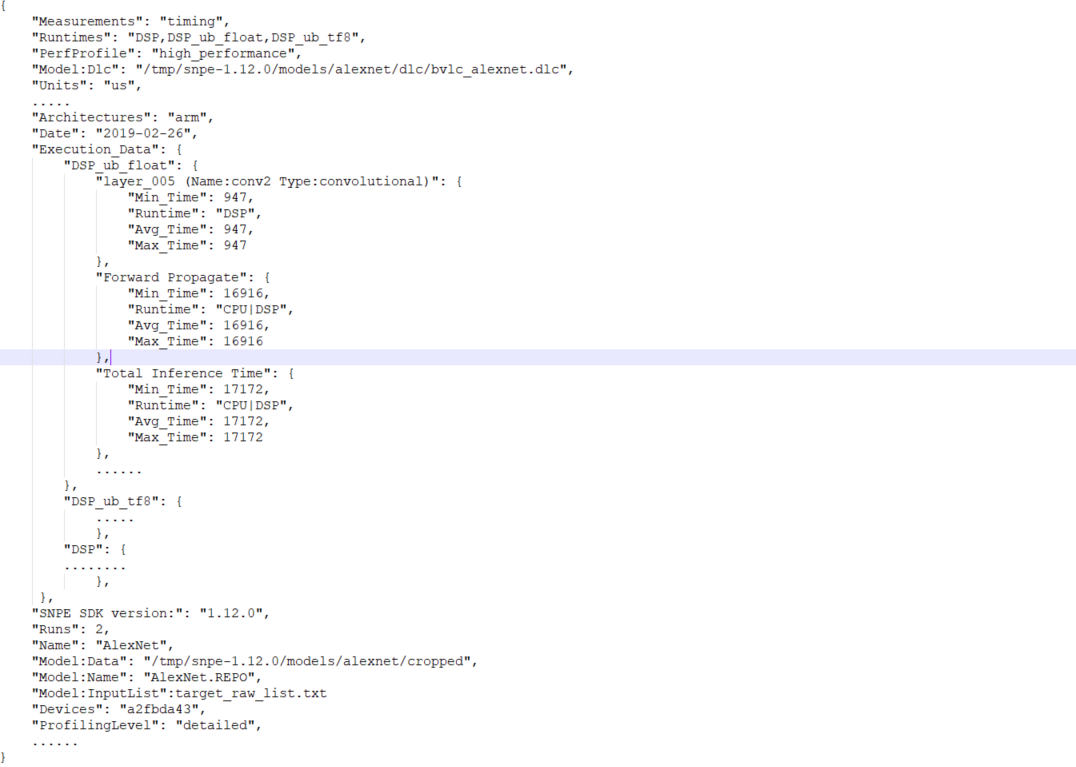
Running the Benchmark with Your Own Network and Inputs
Prepare inputs
Before running the benchmark, a set of inputs need to be ready:
- your_model.dlc
- A text file listing all of your input data. For an example, see: $SNPE_ROOT/models/alexnet/data/image_list.txt
- All of the input data that is listed in the above text file. For an example, see directory $SNPE_ROOT/models/alexnet/data/cropped
- Note: image_list.txt must exactly match the structure of your input directory.
- For more information on preparing your inputs, see: Input Images
Create a Run Configuration
Config structure
The configuration file is a JSON file with a predefined structure. Refer to $SNPE_ROOT/benchmarks/alexnet_sample.json as an example.
All fields are required.
- Name: The name of this configuration, e.g., AlexNet
- HostRootPath: The top level output folder on the host. It can be an absolute path or a relative path to the current working directory.
- HostResultDir: The folder on the host where all benchmark results are put. It can be an absolute path or a relative path to the current working directory.
- DevicePath: The folder on the device where all benchmark-related data and artifacts are put, e.g., /data/local/tmp/snpebm
- Devices: The serial number of the device that the benchmark runs on. Only one device is currently supported.
- Runs: The number of times that the benchmark runs for each of the "Runtime" and "Measurements" run combinations
- Model:
- Name: The name of the DNN model, e.g., alexnet
- Dlc: The folder where the model dlc file is located on the host. It can be an absolute path or a relative path to the current working directory.
- InputList: The text file path that lists all of the input data. It can be an absolute path or a relative path to the current working directory.
- Data: A list of data files or folders that are listed in InputList file. It can be an absolute path or a relative path to the current working directory. If the path is a folder, all contents of that folder will be pushed to the device.
- Runtimes: Possible values are "GPU", "GPU_FP16", "DSP" and "CPU". You can use any combination of these.
- Measurements: Possible values are "timing" and "mem". You can set either one or both of these values. Each measurement type is measured alone for each run.
Optional fields:
- CpuFallback: Possible values are true and false. Indicates whether or not the network can fallback to CPU when a layer is not available on a runtime. Default value is false.
- HostName: Hostname/IP of remote machine to which devices are connected. Default value is 'localhost'.
- BufferTypes: List of user buffertypes. Possible values are ""(empty string), or any combination of "ub_float" and "ub_tf8". If "" is given, it executes for all the runtimes given in RunTimes field. If any userbuffer option is given, it executes for all runtimes in RunTimes along with given userbuffer variants. If this field is absent, it is executed for all possible runtimes(default case).
Architecture support
Android ARM 32-bit and AARCH 64-bit are both supported. In addition to Android, there is limited support for LinuxEmbedded, where only the timing measurement is supported.
Runtime and measurement are concatenated to make a full run combination name, e.g.,
- "GPU_timing": GPU runtime, timing measurement
- "CPU_mem": CPU runtime, memory measurement
Note that for each specified runtime, there are multiple sets of timing measurements which differ only in the tensor format (Using ITensors and Using User Buffers). For example, for the DSP runtime, the following timing measurements are taken:
- "DSP_timing": Timing measurement on DSP runtime using ITensors
- "DSP_ub_tf8_timing": Timing measurement on DSP runtime using UserBuffer with TF8 encoding
- "DSP_ub_float_timing": Timing measurement on DSP runtime using UserBuffer with float encoding
Run the Benchmark
The easiest way to run the benchmark is to specify the -a option, which will run the benchmark on the lone device connected to your computer.
cd $SNPE_ROOT/benchmarks python3 snpe_bench.py -c yourmodel.json -a
The benchmark will do an md5sum on the host files (those specified in the JSON configuration) and on the device files. Because of the md5sum check, files needed for the benchmark run has to be available on the host.
For any file that exists both on host and on the device with mismatch md5, the benchmark will copy the file from host to target and issue a warning message letting you know that the local files do not match the device files. This is done so that you can be sure that the results you get from a benchmark run accurately reflect the files specified in the JSON file.
Other options
-v option
Allows you to override the device ID specified in the config file, so that the same config file can be used across multiple devices. You can use this instead of -a, if you have multiple devices attached.
-o option
Result output base directory override applies only if relative paths are specified for HostRootPath and HostResultsDir. It allows you to pool the output regardless of where you run the benchmark from.
-t option
OS Type override currently supports Android arm (armeabi-v7a), Android aarch64 (arm64-v8a), and LinuxEmbedded devices.
-b option
Allows you to specify type of input and output user buffers.
-p option
Allows you to profile performance in different operating modes.
-l option
Allows you to specify the level of performance profiling.
Reading the Results
Open the results(CSV file or JSON file) in your <HostResultsDir>/latest_results folder to view your results. (<HostResultsDir> is what you specified in your json configuration file.)
Measurement Methodology
In all cases, the snpe-net-run executable is used to load a model and run inputs through the model.
Performance ("timing")
Timing measurements are taken using internal timing utilities inside the SNPE libraries. When snpe-net-run is executed, the libraries will log timing info to a file. This file is then parsed offline to retrieve total inference times and per-layer times.
The total inference times include both the per-layer computation times plus overhead such as data movements between layers, as well as into and out of runtimes, whereas the per-layer times are strictly computational times for each layer. For smaller networks the overhead can be quite significant relative to computational time, particularly when offloading the networks to run on GPU or DSP.
As well, further optimizations present on the GPU/DSP may cause layer times to be mis-attributed, in the case of neuron conv-neuron or fc-neuron pairs. When executing on GPU the total time of the pairs would be assigned to convs, whereas for DSP they would be assigned to the neurons.
Benchmark Dependencies
Binaries that the benchmark script depends on are in the following configuration files, depending on the target architecture, compiler, and STL library:
-
Android 32-bit
- clang - libc++: snpebm/snpebm_artifacts.json
-
Android 64-bit
- clang - libc++: snpebm/snpebm_artifacts_android_aarch64.json
- LinuxEmbedded: snpebm/snpebm_artifacts_le.json