Input Images
In addition to converting the model, SNPE also requires the input image to be in a specific format that might be different from the source framework.
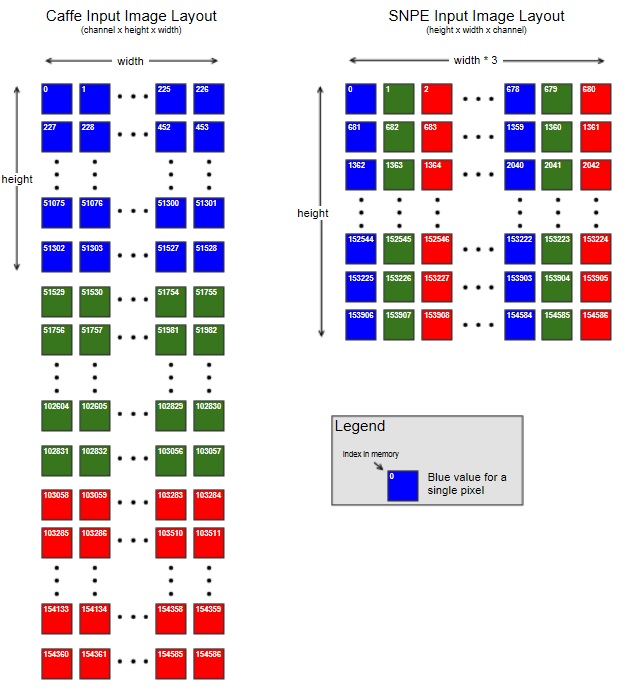
In Caffe, the image is presented as a tensor of shape (batch x channel x height x width), where width is the fastest-changing dimension, followed by height, then color channel. This means that all the pixel values of the first color channel are contiguous in memory, followed by all the pixel values of the next color channel, and so forth. Caffe prepares the images in this format in the convert_imageset tool during the training process.
In SNPE, the image must be presented as a tensor of shape (batch x height x width x channel), where channel is the fastest-changing dimension. This means that values for all the color channels of a single pixel are contiguous in memory, followed by all the color values of the next pixel, and so forth.
If the batch dimension is greater than 1, the individual images have to be manually concatenated together into a single file for each batch.
See the figure below for a visual representations of the two input image memory layouts.
Note:
The channel order used during inference must be the same as that used during training. For example, Imagenet models trained in Caffe require a channel order of BGR.
Input Image for Imagenet Models
The Imagenet models in Caffe (such as bvlc_alexnet, bvlc_googlenet, etc.) are trained with BGR images (blue pixels before green pixels before red pixels). The inference engine must be provided the pixel values in the same channel order.
The following image shows the two different input image memory layouts required by Caffe and SNPE for the bvlc_alexnet model. The input image size is 227x227.
Input Image for MNIST Models
The MNIST models in Caffe (such as lenet) require single-channel grayscale images of size 28x28. Note that while there is only one channel, an input tensor of 4 dimensions is still required in Caffe (1x1x28x28) and SNPE (1x28x28x1).
Output
The output of the example remains the same between Caffe and SNPE: a 1-dimensional tensor containing the probability of each class, for each image in the batch.
For Imagenet models (such as bvlc_alexnet), this is a tensor of size 1000 for the 1000 Imagenet classes.
If the batch dimension of the model is greater than 1, the individual output tensors will be concatenated together along the batch dimension.