Overview
- Non-quantized DLC files use 32 bit floating point representations of network parameters.
- Quantized DLC files use fixed point representations of network parameters, generally 8 bit weights and 8 or 32bit biases. The fixed point representation is the same used in Tensorflow quantized models.
Caffe and Caffe2
The default output of snpe-caffe-to-dlc and tools_snpe-caffe2-to-dlc is a non-quantized model. This means that all the network parameters are left in the 32 floating point representation as present in the original Caffe model. To quantize the model to 8 bit fixed point, see snpe-dlc-quantize. Note that models that are intended to be quantized using snpe-dlc-quantize must have their batch dimension set to 1. A different batch dimension can be used during inference, by resizing the network during initialization.
ONNX
The default output of snpe-onnx-to-dlc is a non-quantized model. This means that all the network parameters are left in the 32 bit floating point representation as present in the original ONNX model. To quantize the model to 8 bit fixed point, see snpe-dlc-quantize. Note that models that are intended to be quantized using snpe-dlc-quantize must have their batch dimension set to 1. A different batch dimension can be used during inference, by resizing the network during initialization.
TensorFlow
The default output of snpe-tensorflow-to-dlc is a non-quantized model. This means that all the network parameters are left in the 32 bit floating point representation as present in the original TensorFlow model. To quantize the model to 8 bit fixed point, see snpe-dlc-quantize. Note that models that are intended to be quantized using snpe-dlc-quantize must have their batch dimension set to 1. A different batch dimension can be used during inference, by resizing the network during initialization.
Choosing Between a Quantized or Non-Quantized Model
Summary
| Runtime | Quantized DLC | Non-Quantized DLC |
|---|---|---|
| CPU or GPU | Compatible. The model is dequantized by the runtime, increasing network initialization time. Accuracy may be impacted. | Compatible. The model is native format for these runtimes. Model can be passed directly to the runtime. May be more accurate than a quantized model. |
| DSP | Compatible. The model is native format for DSP runtime. Model can be passed directly to the runtime. Accuracy may be different than a non-quantized model | Compatible. The model is quantized by the runtime, increasing network initialization time. Accuracy may be different than a quantized model. |
| AIP | Compatible. The model is in supported format for AIP runtime. Model can be passed directly to the runtime. | Incompatible. Non-quantized models are not supported by the AIP runtime. |
Details
-
GPU and CPU
- The GPU and CPU always use floating point (non-quantized) network parameters.
- Using quantized DLC files with GPU and CPU runtimes is supported. Network initialization time will dramatically increase as SNPE will automatically de-quantize the network parameters in order to run on GPU and CPU.
- If network initialization time is a concern, it is recommended to use non-quantized DLC files (default) for both GPU and CPU.
- Quantization of the DLC file does introduce noise, as quantization is lossy.
- The network performance during execute is not impacted by the choice of quantized vs non-quantized DLC files.
-
DSP
- The DSP always uses quantized network parameters.
- Using a non-quantized DLC file on the DSP is supported. Network initialization time will dramatically increase as SNPE will automatically quantize the network parameters in order to run on the DSP.
- It is generally recommended to use quantized DLC files for running on the DSP. In addition to faster network initialization time, using quantized models also reduces peak memory usage during initialization, and decreases DLC file size.
-
AIP
- The AIP runtime always uses quantized network parameters.
- Passing through snpe-dlc-quantize is mandatory for generating the binaries for HTA subnets.
- Using a non-quantized DLC file with the AIP runtime is not supported.
- HTA subnets use the quantized parameters in the DLC.
- HNN (Hexagon NN) subnets use the quantization parameters in the same way DSP runtime does.
-
Balancing DLC file size, network initialization time and accuracy
- If the network will mainly run on the GPU and CPU it is recommended to try both quantized and non-quantized models during development. If a quantized model provides enough accuracy, then it may be used at the expense of increased network initialization time. The benefit is a much smaller DLC file. The tradeoff between accuracy, network initialization time, and DLC file size is application specific.
- If the network will mainly run on the DSP, there is no benefit to using a non-quantized model. As previously stated it will dramatically increase network initialization time and DLC file size, but provide no accuracy benefit.
Quantization Algorithm
This section describes the concepts behind the quantization algorithm used in SNPE. These concepts are used by snpe-dlc-quantize and is also used by SNPE for input quantization when using the DSP runtime.
Overview
Note: SNPE supports multiple quantization modes. The basics of the quantization, regardless of mode, are described here. See Quantization Modes for more information.
- Quantization converts floating point data to Tensorflow-style 8-bit fixed point format
-
The following requirements are satisfied:
- Full range of input values is covered.
- Minimum range of 0.01 is enforced.
- Floating point zero is exactly representable.
-
Quantization algorithm inputs:
- Set of floating point values to be quantized.
-
Quantization algorithm outputs:
- Set of 8-bit fixed point values.
-
Encoding parameters:
- encoding-min - minimum floating point value representable (by fixed point value 0)
- encoding-max - maximum floating point value representable (by fixed point value 255)
-
Algorithm
- Compute the true range (min, max) of input data.
- Compute the encoding-min and encoding-max.
- Quantize the input floating point values.
-
Output:
- fixed point values
- encoding-min and encoding-max parameters
Details
-
Compute the true range of the input floating point data.
- finds the smallest and largest values in the input data
- represents the true range of the input data
-
Compute the encoding-min and encoding-max.
- These parameters are used in the quantization step.
-
These parameters define the range and floating point values that will be representable by the fixed point format.
- encoding-min: specifies the smallest floating point value that will be represented by the fixed point value of 0
- encoding-max: specifies the largest floating point value that will be represented by the fixed point value of 255
- floating point values at every step size, where step size = (encoding-max - encoding-min) / 255, will be representable
- encoding-min and encoding-max are first set to the true min and true max computed in the previous step
-
First requirement: encoding range must be at least a minimum of 0.01
- encoding-max is adjusted to max(true max, true min + 0.01)
-
Second requirement: floating point value of 0 must be exactly representable
- encoding-min or encoding-max may be further adjusted
-
Handling 0.
-
Case 1: Inputs are strictly positive
- the encoding-min is set to 0.0
- zero floating point value is exactly representable by smallest fixed point value 0
-
e.g. input range = [5.0, 10.0]
- encoding-min = 0.0, encoding-max = 10.0
-
Case 2: Inputs are strictly negative
- encoding-max is set to 0.0
- zero floating point value is exactly representable by the largest fixed point value 255
-
e.g. input range = [-20.0, -6.0]
- encoding-min = -20.0, encoding-max = 0.0
-
Case 3: Inputs are both negative and positive
- encoding-min and encoding-max are slightly shifted to make the floating point zero exactly representable
-
e.g. input range = [-5.1, 5.1]
- encoding-min and encoding-max are first set to -5.1 and 5.1, respectively
- encoding range is 10.2 and the step size is 10.2/255 = 0.04
- zero value is currently not representable. The closest values representable are -0.02 and +0.02 by fixed point values 127 and 128, respectively
- encoding-min and encoding-max are shifted by -0.02. The new encoding-min is -5.12 and the new encoding-max is 5.08
- floating point zero is now exactly representable by the fixed point value of 128
-
Case 1: Inputs are strictly positive
-
Quantize the input floating point values.
- encoding-min and encoding-max parameter determined in the previous step are used to quantize all the input floating values to their fixed point representation
-
Quantization formula is:
- quantized value = round(255 * (floating point value - encoding.min) / (encoding.max - encoding.min))
- quantized value is also clamped to be within 0 and 255
-
Outputs
- the fixed point values
- encoding-min and encoding-max parameters
Quantization Example
-
Inputs:
- input values = [-1.8, -1.0, 0, 0.5]
- encoding-min is set to -1.8 and encoding-max to 0.5
- encoding range is 2.3, which is larger than the required 0.01
- encoding-min is adjusted to −1.803922 and encoding-max to 0.496078 to make zero exactly representable
- step size (delta or scale) is 0.009020
-
Outputs:
- quantized values are [0, 89, 200, 255]
Dequantization Example
-
Inputs:
- quantized values = [0, 89, 200, 255]
- encoding-min = −1.803922, encoding-max = 0.496078
- step size is 0.009020
-
Outputs:
- dequantized values = [−1.8039, −1.0011, 0.0000, 0.4961]
Bias BitWidth
SNPE currently supports a default quantization bit width of 8 for both weights and biases. The bias bitwidth, however, can be overriden to use 32 bit quantization by specifying the command line option "--bias_bitwidth 32" from snpe-dlc-quantize. For some models, using 32bit biases may give a small improvement in accuracy. Unfortunately it is difficult to predict which models may benefit from this since model architectures, weight distributions, etc all have an impact on quantization performance.
Activation BitWidth
SNPE also supports, quantization bitwidth of 16 for activation.(See Notes)
To enable 16-bit fixed point inference, specify quantization bitwidth of activations to 16 while keeping that of weights to 8. Passing the command line options: “–act_bitwidth 16 –weights_bitwidth 8” to snpe-dlc-quantize, will generate quantized model files with 16-bit activations and 8-bit weights.
It is recommended to use UserBuffer TF16 as input/output data format for better efficiency. In this case, users of SNPE need quantize/dequantize input/output data on their own if floating point data are used. When testing with snpe-net-run,command line option “–userbuffer_tfN 16” can be used to select UserBuffer TF16 mode.
ITensor and UserBuffer floating point format can still be used with 16-bit integer inference with less efficient quantization applied internally.
Quantization Modes
SNPE supports multiple quantization modes, the difference is in how quantization parameters are chosen.
Default Quantization Mode
The default mode has been described above, and uses the true min/max of the data being quantized, followed by an adjustment of the range to ensure a minimum range and to ensure 0.0 is exactly quantizable.
Enhanced Quantization Mode
Enhanced quantization mode (invoked by using the "use_enhanced_quantizer" parameter to snpe-dlc-quantize) uses an algorithm to try to determine a better set of quantization parameters to improve accuracy. The algorithm may pick a different min/max value than the default quantizer, and in some cases it may set the range such that some of the original weights and/or activations cannot fall into that range. However, this range does produce better accuracy than simply using the true min/max. The enhanced quantizer can be enabled independently for weights and activations by appending either "weights" or "activations" after the option.
This is useful for some models where the weights and/or activations may have "long tails". (Imagine a range with most values between -100 and 1000, but a few values much greater than 1000 or much less than -100.) In some cases these long tails can be ignored and the range -100, 1000 can be used more effectively than the full range.
Enhanced quantizer still enforces a minimum range and ensures 0.0 is exactly quantizable.
Adjusted Weights Quantization Mode
This mode is used only for quantizing weights to 8 bit fixed point(invoked by using the "use_adjusted_weights_quantizer" parameter to snpe-dlc-quantize), which uses adjusted min or max of the data being quantized other than true min/max or the min/max that exclude the long tail. This has been verified to be able to provide accuracy benefit for denoise model specifically. Using this quantizer, the max will be expanded or the min will be decreased if necessary.
Adjusted weights quantizer still enforces a minimum range and ensures 0.0 is exactly quantizable.
Enhanced Quantization Techniques
Quantization can be a difficult problem to solve due to the myriad of training techniques, model architectures, and layer types. In an attempt to mitigate quantization problems two new model preprocessing techniques have been added to snpe-dlc-quantize that may improve quantization performance on models which exhibit sharp drops in accuracy upon quantization.
The two new techniques introduced are CLE (Cross Layer Equalization) and BC (Bias Correction).
CLE works by scaling the convolution weight ranges in the network by making use of a scale-equivariance property of activation functions. In addition, the process absorbs high biases which may be result from weight scaling from one convolution layer to a subsequent convolution layer.
BC corrects the biased error that is introduced in the activations during quantization. It does this by accumulating convolution/MatMul activation data from the floating-point model and the quantized model and then corrects for the statistical bias on the layer’s output. This correction is added to the bias of the layer in question.
Enhanced Quantization Techniques: Limitations
In many cases CLE+BC may enable quantized models to return to close to their original floating-point accuracy. There are some caveats/limitations to the current algorithms:
-
CLE operates on specific patterns of operations that all exist in a single branch (outputs cannot be consumed by more than one op). The matched operation patterns (r=required, o=optional) are:
- Conv(r)->Batchnorm(r)->activation(o)->Conv(r)->Batchnorm(r)->activation(o)
- Conv(r)->Batchnorm(r)->activation(o)->DepthwiseConv(r)->Batchnorm(r)->activation(o)->Conv(r)->Batchnorm(r)->activation(o)
- The CLE algorithm currently only supports Relu activations. Any Relu6 activations will be automatically changed to Relu and any activations other than these will cause the algorithm to ignore the preceding convolution. Typically the switch from Relu6->Relu is harmless and does not cause any degradation in accuracy, however some models may exhibit a slight degradation of accuracy. In this case, CLE+BC can only recover accuracy to that degraded level, and not to the original float accuracy.
- CLE requires batchnorms (specifically detectable batchnorm beta/gamma data) be present in the original model before conversion to DLC for the complete algorithm to be run and to regain maximum accuracy. For Tensorflow, the beta and gamma can sometimes still be found even with folded batchnorms, so long as the folding didn't fold the parameters into the convolution's static weights and bias. If it does not detect the required information you may see a message that looks like: "Invalid model for HBA quantization algorithm." This indicates the algorithm will only partially run and accuracy issues may likely be present.
Typically CLE and BC are best when used together as they complement one another. CLE is very fast (seconds), however BC can be extremely slow (minutes to hours) as quantization data must be run through the network repeatedly as corrections are made. When time is critical it might be prudent to try CLE first and check the accuracy of the resulting model. If the accuracy is good (within a couple % of the floating-point model) then CLE+BC should be run on the original model and will likely give better results. In cases where the accuracy is still poor BC is unlikely to provide much additional accuracy gain.
To run the typical use case, CLE+BC, pass the "--optimizations cle --optimizations bc" to snpe-dlc-quantize.
To run only CLE pass the "--optimizations cle" to snpe-dlc-quantize.
The original converted float model should always be used as input to snpe-dlc-quantize. Passing quantized models back to the quantizer is not supported and will result in undefined behavior. In addition, BC should not be run on its own without CLE as it won’t fix major issues with weight/activation quantization.
More information about the algorithms can be found here: https://arxiv.org/abs/1906.04721
Quantization Impacts
Quantizing a model and/or running it in a quantized runtime (like the DSP) can affect accuracy. Some models may not work well when quantized, and may yield incorrect results. The metrics for measuring impact of quantization on a model that does classification are typically "Mean Average Precision", "Top-1 Error" and "Top-5 Error". These metrics published in SNPE release notes for various models.
Mixed Precision and FP16 Support
Mixed Precision enables specifying different bit widths (e.g. 8 or 16) or datatypes (integer or floating point) for different operations within the same graph. Data type conversion operations are automatically inserted when activation precision or data type is different between successive operations. Graphs can have a mix of floating-point and fixed-point data types. Each operation can have different precision for weights and activations. However, for a particular operation, either all inputs, outputs and parameters (weights/biases) will be floating-point or all will be fixed-point format.
Quantization Overrides
If the option –quantization_overrides is provided during model conversion the user can provide a json file with parameters to use for quantization. These will be cached along with the model and can be used to override any quantization data carried from conversion (eg TF fake quantization) or calculated during the normal quantization process in snpe-dlc-quantize. To override the params during snpe-dlc-quantize the option –override_params must be passed, and the cached values will be used instead. The json format is defined as per AIMET specification and can be found below.
There are two sections in the json, a section for overriding operator output encodings called "activation_encodings" and a section for overriding parameter (weight and bias) encodings called "param_encodings". Both must be present in the file, but can be empty if no overrides are desired.
An example with all of the currently supported options:
{
"activation_encodings": {
"Conv1:0": [
{
"bitwidth": 8,
"max": 12.82344407824954,
"min": 0.0,
"offset": 0,
"scale": 0.050288015993135454
}
],
"input:0": [
{
"bitwidth": 8,
"max": 0.9960872825108046,
"min": -1.0039304197656937,
"offset": 127,
"scale": 0.007843206675594112
}
]
},
"param_encodings": {
"Conv2d/weights": [
{
"bitwidth": 8,
"max": 1.700559472933134,
"min": -2.1006477158567995,
"offset": 140,
"scale": 0.01490669485799974
}
]
}
}
Under "activation_encodings" the names (eg "Conv1:0") represent the output tensor names where quantization should be overriden. Under "param_encodings" the names represent the weights or biases for which the encodings will be specified. A brief breakdown of the common parameters:
- bitwidth (int, required) - The bitwidth to use for quantization. Note that this much match the existing bitwidth support for the runtime on which the model will be run.
- max (float, required) - The largest number in the distribution or desired range.
- min (float, required) - The smalled number in the distribution or desired range.
- offset (int) - The integer offset indicating the zero point (ie The point at which 0 is exactly represnted)
- scale (float) - The value indicating the integer size divided by the desired distribution range
Note that it is not required to provide scale (also referred to as delta) and offset (zero point). If they are provided they will be used, otherwise they will be calulated from the provided bitwidth, min, and max parameters.
Note :- Quantization bit width 16 for activation, supported from Snapdragon 865/765 onwards on certain runtimes and currently not enable for all ops.
Float16 (half-precision) additionally enables converting the entire models to FP16 or selecting between FP16 and FP32 data-types for the float ops in case of mixed precision graphs with a mix of floating point and integer ops. The different modes of using mixed precision are described below.
-
No override: If no –quantization_overrides flag is given with an encoding file, all activations are quantized as per –act_bitwidth (default 8) and parameters are quantized as per –weight_bitwidth/–bias_bitwidth (default 8/8) respectively.
-
Full override: If –quantization_overrides flag is given along with encoding file specifying encodings for all ops in the model. In this case, for all ops defined as integer as per encoding file (dtype=’int’ in encoding json), the bitwidth with be set as per JSON. The ops defined as float in encoding file (dtype=’float’), will be marked as FP16 for both activations and weights if –float_bitwidth 16 is given on command line. Else they will be marked as FP32. i.e. For ops marked as float in encodings json, the bitwidth in encodings json will be ignored and set as either as 16-bit or 32-bit as per –float_bitwidth flag.
-
Partial override: If –quantization_overrides flag is given along with encoding file specifying partial encodings (i.e. encodings are missing for some ops), the following will happen.
-
Layers for which encoding are NOT available in json file are encoded in the same manner as the no override case i.e. defined as integer with bitwidth defined as per –act_bitwidth/–weight_bitwidth/–bias_bitwidth (or their default values 8/8/8).
- Layers for which encoding are available in json are encoded in same manner as full override case.
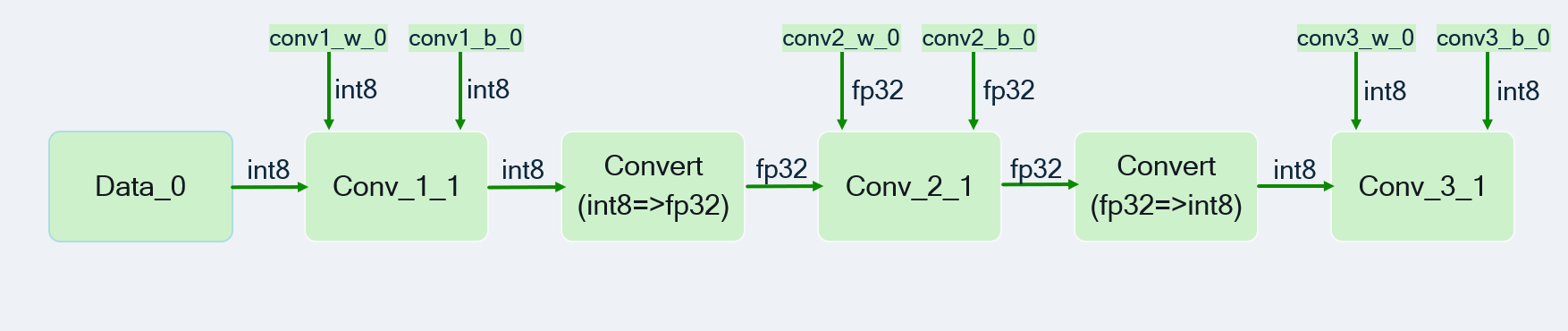
We show a sample json for network with 3 Conv2d ops. The first and third Conv2d ops are INT8 while the second Conv2d op is marked as FP32. The FP32 op (namely conv2_1) is sandwiched between two INT8 ops in “activation_encodings”, hence convert ops will be inserted before and after the FP32 op. The corresponding weights and biases for conv2_1 are also marked as floating-point in the JSON in “param_encodings”.
{ "activation_encodings": { "data_0": [ { "bitwidth": 8, "dtype": "int" } ], "conv1_1": [ { "bitwidth": 8, "dtype": "int" } ], "conv2_1": [ { "bitwidth": 32, "dtype": "float" } ], "conv3_1": [ { "bitwidth": 8, "dtype": "int" } ] }, "param_encodings": { "conv1_w_0": [ { "bitwidth": 8, "dtype": "int" } ], "conv1_b_0": [ { "bitwidth": 8, "dtype": "int" } ], "conv2_w_0": [ { "bitwidth": 32, "dtype": "float" } ], "conv2_b_0": [ { "bitwidth": 32, "dtype": "float" } ], "conv3_w_0": [ { "bitwidth": 8, "dtype": "int" } ], "conv3_b_0": [ { "bitwidth": 8, "dtype": "int" } ] } }The ops that are not present in json will be assumed to be fixed-point and the bit widths will be selected according to –act_bitwidth/–weight_bitwidth/–bias_bitwidth respectively. Note: Currently the float bitwidth specified in the encoding json is ignored and instead the bitwidth specified with –float_bitwidth converter option is used by the quantizer.
{ "activation_encodings": { "conv2_1": [ { "bitwidth": 32, "dtype": "float" } ] }, "param_encodings": { "conv2_w_0": [ { "bitwidth": 32, "dtype": "float" } ], "conv2_b_0": [ { "bitwidth": 32, "dtype": "float" } ] } }The following quantized mixed-precision graph will be generated based on the JSON shown above. Please note that the convert operations are added appropriately to convert between float and int types and vice-versa.
-