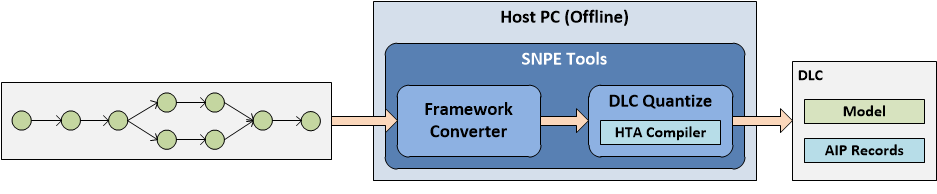
Running a model on Hexagon Tensor Accelerator (HTA) requires quantization of the model, and generating binaries for the section(s) that run on HTA. Both are done using the snpe-dlc-quantize tool, which is extended to include the HTA compiler inside.
For example, the following command converts an Inception v3 DLC file into a quantized Inception v3 DLC file, and generate the HTA section to run the entire model on HTA.
snpe-dlc-quantize --input_dlc inception_v3.dlc --input_list image_file_list.txt
--output_dlc inception_v3_quantized.dlc --enable_hta
All parameters besides the last one (enable_hta) are same as for regular quantization, and explained on Quantizing a Model. Adding this parameter triggers generation of HTA section(s) on the model provided, and adding the compiled section(s) to AIP records into the DLC. If the HTA compiler cannot process/compile any section of the network, snpe-dlc-quantize issues an error message. However, the DLC will still be created - just without the HTA section(s).
Model Partitioning
By default, the HTA compiler automatically partitions the network to maximize the sections that run on the HTA.
In this case, when the model is loaded, the AIP runtime runs the non-HTA sections on HVX, using Hexagon NN.
Any sections not handled by the AIP runtime may fall back to be executed on the CPU runtime if CPU fallback is enabled.
In certain cases it may be desirable to partition a network manually, and pick partition points that may be different from what the compiler would produce automatically. This may be a prefable option when it is known in advance that a certain section of the network is not supported to run on HTA, requesting only the remaining section to be compiled for HTA, or for performance benefits.
In all cases, the SNPE snpe-dlc-quantize tool creates records that store metadata about the HTA subnets and the compiled binaries produced by the HTA compiler for the specified sections.
In addition it also detects and creates records for HNN subnets to cover the rest of the model and store metadata about them that specifies buffer connectivity with other HTA subnets determined by the partitioning.
All of these records are stored in the DL container in a format that is parsed at runtime when loading the model.
To manually specify HTA sections with use when partitioning the model, an additional argument "hta_partitions" should be passed to snpe-dlc-quantize in addition to "enable_hta".
The partition boundaries are specified as comma-separated (start-end) pairs that refer to the IDs of the layers that must belong to the partition.
For example, the following command converts an Inception v3 DLC file into a quantized Inception v3 DLC file, and generates a single HTA section for layers 0-11.
snpe-dlc-quantize --input_dlc inception_v3.dlc --input_list image_file_list.txt
--output_dlc inception_v3_quantized.dlc --enable_hta --hta_partitions 0-11
The following command extends the partitioning to multiple HTA partitions, 0-11 and 177-215 in this case.
snpe-dlc-quantize --input_dlc inception_v3.dlc --input_list image_file_list.txt
--output_dlc inception_v3_quantized.dlc --enable_hta --hta_partitions 0-11,177-215
Notes:
- The process of HTA compilation deletes any older AIP records that may already exist in the DLC from previous runs of snpe-dlc-quantize with --enable_hta.
It is recommended that users start with the original DLC for HTA compilation in order to not inadvertently lose previously generated AIP records. - Creating a large number of partitions within an AIP subnet may result both in sub-optimal performance and degraded accuracy at runtime due to the repeated re-quantizations and format conversions that happen between the HVX and HNN subnets.
- One way of optimizing AIP performance in such scenarios is by re-ordering the unique IDs associated with each of the layers in the source network (before conversion to DLC) such that offline compilation results in more meaningful partitions and lesser fragmentation in the network.